Sixteen APL Amuse-Bouches
Roger K.W. Hui
| The amuse-bouche is the best way … to express big ideas in small bites. |
| — Jean-Georges Vongerichten, 2002 |
| |
| Such were the vagaries of what may have been the most powerful computer
language ever hatched by a Canadian.
Yes, I know that James Gosling, an alumnus of the University of Calgary,
was the “father of Java.” He and I have talked about it.
And yes, there is a now a game called “Perl Golf” in which
you try to do the most work in that scripting language with the fewest number of (key-) strokes.
Java and Perl are good and useful and popular, but APL was … beautiful.
|
| — Tom Keenan,
Business Edge, 2004 |
0. (x>0)-(x<0)
|
| |
Signum of x for real x ,
assuming the values 1 , 0 ,
or ¯1 according as x
is strictly positive, 0, or strictly negative.
The phrase dates from the earliest days of APL,
being found in section 1.4 of A Programming Language
[0].
Three decades later, the idea was adopted by Knuth
[1],
who wrote that “Iverson’s convention” led to improvements in exposition and technique.
Some writers call these “data-driven conditionals”
[2];
during a discussion between Phil Last, John Scholes, and myself
it was suggested that they be called “array logic”
[3].
The usefulness of array logic in APL is due to the following:
| • | Boolean functions have value 0 and 1 rather than true and false
[4, #implementers2].
|
| • | Functions apply to entire arrays, as in, for
example, +/x>100 to compute the number of elements of vector x
greater than 100
[4, #Maple].
|
| • | A simple function precedence (“right to left”). |
Amuse-bouches 0, 2, 4, D, and E use array logic.
|
1. (+⌿÷≢) x
|
| |
The average of x .
The construct +⌿÷≢ is a fork, a 3-train.
Using +⌿ and ≢ instead of the more familiar +/ and ⍴
is superior for reasons described in
[5].
|
2. x⌹x=x
|
| |
A shortest phrase for the average
of vector x . Note that + / ⌿ ÷ ⍴ ≢ are not used.
The idea originated with Timo Seppälä at APL82
[6].
To see why it works, start with the definition
y⌹x ←→ (⌹(+⍉x)+.×x)+.×(+⍉x)+.×y
which defines the rectangular case in terms of the square case.
| x⌹x=x |
| x⌹w | w←x=x |
| (⌹(+⍉w)+.×w)+.×(+⍉w)+.×x | definition of ⌹ |
| (⌹(⍉w)+.×w)+.×(⍉w)+.×x | w is non-complex |
| (÷≢x)+.×w+.×x | w is (≢x)⍴1; w+.×w is ≢x |
| (÷≢x)+.×+⌿x | ((≢x)⍴1)+.×x ←→ +⌿x |
| (÷≢x)×+⌿x | LHS and RHS of +.× are scalars |
| (+⌿x)÷≢x |
Alternatively, y⌹x computes a linear regression for y wherein the constant term
is the mean of y ; that is, the best least square
“fit” of a vector by a single number,
is its mean.
|
3. x⍳x
|
| |
Index-of with both arguments being the same, an instance of a “selfie”
[7]. x⍳x
are like ID numbers; questions of identity on x
can often be answered more efficiently on x⍳x than on x itself.
The x⍳x selfie occurs in several important and useful computations:
| ((⍳≢x)=x⍳x)⌿x | nub (unique) |
| (x⍳x)∘.=(x⍳y) | an efficient computation for x∧.=⍉y for matrices x and y
[8]
|
| (x⍳x)∘.=(x⍳y) | an efficient computation for x∘.≡y for non-simple vector x
[9]
|
| (⍉↑x⍳¨x)⍳(⍉↑x⍳¨y) | inverted table index-of
[10] |
| (x⍳x) f⌸ y | equivalent to x f⌸ y |
|
4. '.⎕'[x∘.>⍳⌈/x]
|
| |
A bar chart of non-negative integer vector x .
x← 3 1 4 1 5 9
'.⎕'[x∘.>⍳⌈/x]
⎕⎕⎕......
⎕........
⎕⎕⎕⎕.....
⎕........
⎕⎕⎕⎕⎕....
⎕⎕⎕⎕⎕⎕⎕⎕⎕
I encountered this phrase when I first learned APL in the mid 1970s.
By then, it was part of the APL milieu, found in STATPACK
[11]
and APL in Exposition
[12, p.13].
(I believe I saw it in the former.)
The phrase brought home to me that indices can be entire arrays.
|
5. +\1 ¯1 0['()'⍳x]
|
| |
Depth of parentheses nesting.
x←'⍵((∇<S),=S,(∇>S))⍵⌷⍨?≢⍵'
x ,[¯0.5] +\1 ¯1 0['()'⍳x]
⍵ ( ( ∇ < S ) , = S , ( ∇ > S ) ) ⍵ ⌷ ⍨ ? ≢ ⍵
0 1 2 2 2 2 1 1 1 1 1 2 2 2 2 1 0 0 0 0 0 0 0
The phrase has an ancient and storied history. As recounted by Alan Perlis
[13]:
I was at a meeting in Newcastle, England, where I’d been invited to give a talk,
as had Don Knuth of Stanford, Ken Iverson from IBM, and a few others as well.
I was sitting in the audience sandwiched between two very esteemed people
in computer science and computing —
Fritz Bauer, who runs computing in Bavaria from his headquarters in Munich,
and Edsger Dijkstra, who runs computing all over the world
from his headquarters in Holland.
Ken was showing some slides — and one of his slides had something on it
that I was later to learn was an APL one-liner.
And he tossed this off as an example of the expressiveness of the APL notation.
I believe the one-liner was one of the standard ones for indicating
the nesting level of the parentheses in an algebraic expression.
But the one-liner was very short — ten characters, something like that —
and having been involved with programming things like that for a long time
and realizing that it took a reasonable amount of code to do,
I looked at it and said, “My God, there must be something in this language.”
Bauer, on my left, didn’t see that.
What he saw or heard was Ken’s remark that APL is an extremely appropriate language
for teaching algebra, and he muttered under his breath to me,
in words I will never forget, “As long as I am alive,
APL will never be used in Munich.”
And Dijkstra, who was sitting on my other side,
leaned toward Bauer and said, “Nor in Holland.”
The three of us were listening to the same lecture,
but we obviously heard different things.
|
6. x[⍋⍒(⍴x)⍴0 1]
|
| |
Perfect shuffle, a special case of a solution to the more general mesh
problem described by Ken Iverson
[0, §1.9]
and solved by Luthor Woodrum
[14].
The phrase was found on the back of I.P. Sharp T-shirts in the 1970s and 1980s.
x←'ABCDEFGHIJKLMNOPQ'
x[⍋⍒(⍴x)⍴0 1]
IAJBKCLDMENFOGPHQ
The phrase ⍋⍒n⍴0 1 is a permutation of length n .
Its order is the minimum number of times a perfect shuffle has to be applied
to yield the original argument
[15,
16].
The sequence of these orders is A024222 in the indispensible On-line Encyclopedia of Integer Sequences
[17].
|
7. Q←{1≥≢⍵:⍵ ⋄ S←{⍺⌿⍨⍺ ⍺⍺ ⍵} ⋄ ⍵((∇<S),=S,(∇>S))⍵⌷⍨?≢⍵}
|
| |
Quicksort
[18].
The “pivot” ⍵⌷⍨?≢⍵ is randomly
chosen. ((∇<S),=S,(∇>S)) is a fork, selecting the parts of ⍵
which are less than the pivot, equal to the pivot, and greater than the pivot.
The function is recursively applied to the first and the last of these three parts.
⎕←x←?13⍴20
2 2 7 10 10 11 3 10 14 5 9 1 16
Q x
1 2 2 3 5 7 9 10 10 10 11 14 16
The variant Q1 obtains by enclosing each of the
three parts.
Its result exhibits an interesting structure.
The middle item of each triplet is the value of the pivot
at each recursion.
Since the pivot is randomly chosen the result of Q1
can be different on the same argument.
Q1←{1≥≢⍵:⍵ ⋄ S←{⍺⌿⍨⍺ ⍺⍺ ⍵} ⋄
⍵((⊂∘∇<S),(⊂=S),(⊂∘∇>S))⍵⌷⍨?≢⍵}
Q1 x
┌─────────┬─┬────────────────────────────────┐
│┌─┬───┬─┐│5│┌┬─┬───────────────────────────┐│
││1│2 2│3││ │││7│┌─┬────────┬──────────────┐││
│└─┴───┴─┘│ │││ ││9│10 10 10│┌┬──┬────────┐│││
│ │ │││ ││ │ │││11│┌┬──┬──┐││││
│ │ │││ ││ │ │││ │││14│16│││││
│ │ │││ ││ │ │││ │└┴──┴──┘││││
│ │ │││ ││ │ │└┴──┴────────┘│││
│ │ │││ │└─┴────────┴──────────────┘││
│ │ │└┴─┴───────────────────────────┘│
└─────────┴─┴────────────────────────────────┘
Q1 x
┌────────────────────────────────┬──┬────────┐
│┌────────────────────┬────────┬┐│11│┌┬──┬──┐│
││┌──────────────┬─┬─┐│10 10 10│││ │││14│16││
│││┌─┬───┬──────┐│7│9││ │││ │└┴──┴──┘│
││││1│2 2│┌─┬─┬┐││ │ ││ │││ │ │
││││ │ ││3│5││││ │ ││ │││ │ │
││││ │ │└─┴─┴┘││ │ ││ │││ │ │
│││└─┴───┴──────┘│ │ ││ │││ │ │
││└──────────────┴─┴─┘│ │││ │ │
│└────────────────────┴────────┴┘│ │ │
└────────────────────────────────┴──┴────────┘
|
8. P ← ↑ {(0∘,+,∘0)⍣⍵,1}¨∘⍳
|
| |
Pascal’s triangle
[19].
P 10
1 0 0 0 0 0 0 0 0 0
1 1 0 0 0 0 0 0 0 0
1 2 1 0 0 0 0 0 0 0
1 3 3 1 0 0 0 0 0 0
1 4 6 4 1 0 0 0 0 0
1 5 10 10 5 1 0 0 0 0
1 6 15 20 15 6 1 0 0 0
1 7 21 35 35 21 7 1 0 0
1 8 28 56 70 56 28 8 1 0
1 9 36 84 126 126 84 36 9 1
10 ↑ (,∘.+⍨⍳10) {+/⍵}⌸ ,P 10
1 1 2 3 5 8 13 21 34 55
The expression (0,x)+(x,0) or its commute,
which generates the next set of binomial coefficients, is present
in the document that introduced APL\360 in 1967
[20, Fig.1]
and the one that introduced J in 1990
[21, Gc&Gd];
in Elementary Functions: An Algorithmic Treatment in 1966
[22, p.69],
in APL\360 User’s Manual in 1968
[23, A.5],
in Algebra: An Algorithmic Treatment in 1972
[24, p.141],
in Introducing APL to Teachers in 1972
[25, p.22],
in An Introduction to APL for Scientists and Engineers in 1973
[26, p.19],
in Elementary Analysis in 1976
[27, ex.1.68],
in Programming Style in APL in 1978
[28, §6],
in Notation as a Tool of Thought in 1980
[29, A.3],
in A Dictionary of APL in 1987
[30, m∇n],
and probably others.
∘.!⍨⍳n also computes Pascal’s triangle of order n .
It is shorter, but is less interesting algorithmically and historically.
|
9. +∘÷\n⍴1
|
| |
Convergents to the golden mean by continued fractions
[31].
+∘÷\16⍴1
1 2 1.5 1.66667 1.6 1.625 1.61538 1.61905 1.61765 1.61818
1.61798 1.61806 1.61803 1.61804 1.61803 1.61803
1 ∧ +∘÷\16⍴1
1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
|
A. (2 ÷⍨ ⊢ + ÷)\ n⍴x
|
| |
Convergents to the square root of x by Newton’s method
[32].
The operand of \ is a fork,
itself a composition of two forks (2÷⍨(⊢+÷)) and equivalent
to {0.5×⍵+⍺÷⍵} .
⎕←t← (2 ÷⍨ ⊢ + ÷)\ 7⍴2
2 1.5 1.41667 1.41422 1.41421 1.41421 1.41421
(2*0.5) - t
¯0.585786 ¯0.0857864 ¯0.0024531 ¯0.0000021239 ¯1.59472e¯12
2.22045e¯16 2.22045e¯16
Since the phrase uses only rational operations,
it yields rational convergents when applied to rational arguments.
The following result is computed in J:
2 3r2 17r12 577r408 665857r470832 886731088897r627013566048
1572584048032918633353217r1111984844349868137938112
|
B. x (+⌿ ×⍤¯1)⍤1 2 ⊢y
|
| |
Inner product using row-at-a-time operation. For example:
x←?3 4⍴100
y←?4 5⍴100
(x+.×y) ≡ x (+⌿ ×⍤¯1)⍤1 2 ⊢y
1
The main advantages of row-at-a-time
over the conventional row-by-column
are better cache utilization and
ability to exploit sparsity
[33]
and
[34, #IC2013].
Note: The Dyalog implementation of +.× is already row-at-a-time,
so there is no need to resort to the circumlocution.
|
C. r←,⍳⊢ ⋄ (r G) ≡ r ∘.{⍺[⍵]}⍨ ↓r G
|
| |
The finite case of Cayley’s theorem
[35, §4.4]:
every group G is isomorphic to a subgroup of the group of permutations.
For example:
⎕←T←2 2∘⍴¨(4⍴2)∘⊤¨9 6 7 11 13 14
┌───┬───┬───┬───┬───┬───┐
│1 0│0 1│0 1│1 0│1 1│1 1│
│0 1│1 0│1 1│1 1│0 1│1 0│
└───┴───┴───┴───┴───┴───┘
⎕←G←∘.(≠.∧)⍨T
┌───┬───┬───┬───┬───┬───┐
│1 0│0 1│0 1│1 0│1 1│1 1│
│0 1│1 0│1 1│1 1│0 1│1 0│
├───┼───┼───┼───┼───┼───┤
│0 1│1 0│1 1│1 1│0 1│1 0│
│1 0│0 1│0 1│1 0│1 1│1 1│
├───┼───┼───┼───┼───┼───┤
│0 1│1 0│1 1│1 1│0 1│1 0│
│1 1│1 1│1 0│0 1│1 0│0 1│
├───┼───┼───┼───┼───┼───┤
│1 0│0 1│0 1│1 0│1 1│1 1│
│1 1│1 1│1 0│0 1│1 0│0 1│
├───┼───┼───┼───┼───┼───┤
│1 1│1 1│1 0│0 1│1 0│0 1│
│0 1│1 0│1 1│1 1│0 1│1 0│
├───┼───┼───┼───┼───┼───┤
│1 1│1 1│1 0│0 1│1 0│0 1│
│1 0│0 1│0 1│1 0│1 1│1 1│
└───┴───┴───┴───┴───┴───┘
T are the non-singular 2-by-2 boolean matrices,
and G is its group table under boolean matrix multiplication.
The function r←,⍳⊢ relabels a group
table according to its index in its ravel (cf. x⍳x);
such relabelling, like displaying in a different font,
does not affect group-theoretic properties.
r ← , ⍳ ⊢
r G
0 1 2 3 4 5
1 0 4 5 2 3
2 3 5 4 1 0
3 2 1 0 5 4
4 5 3 2 0 1
5 4 0 1 3 2
The rows of r G are permutations,
and the relabeled version of its group table
as permutations is the same as the relabelling of the original group:
(r G) ≡ r ∘.{⍺[⍵]}⍨ ↓r G
1
|
| D. Symmetries of the square
[35, §4.4]
and
[36].
|
| |
D8
┌──┬──┬──┬──┬──┬──┬──┬──┐
│⊢ │⍒ │⍒⍒│⍋⌽│⌽ │⍋ │⍋⍒│⍒⌽│
├──┼──┼──┼──┼──┼──┼──┼──┤
│⍒ │⍒⍒│⍋⌽│⊢ │⍒⌽│⌽ │⍋ │⍋⍒│
├──┼──┼──┼──┼──┼──┼──┼──┤
│⍒⍒│⍋⌽│⊢ │⍒ │⍋⍒│⍒⌽│⌽ │⍋ │
├──┼──┼──┼──┼──┼──┼──┼──┤
│⍋⌽│⊢ │⍒ │⍒⍒│⍋ │⍋⍒│⍒⌽│⌽ │
├──┼──┼──┼──┼──┼──┼──┼──┤
│⌽ │⍋ │⍋⍒│⍒⌽│⊢ │⍒ │⍒⍒│⍋⌽│
├──┼──┼──┼──┼──┼──┼──┼──┤
│⍋ │⍋⍒│⍒⌽│⌽ │⍋⌽│⊢ │⍒ │⍒⍒│
├──┼──┼──┼──┼──┼──┼──┼──┤
│⍋⍒│⍒⌽│⌽ │⍋ │⍒⍒│⍋⌽│⊢ │⍒ │
├──┼──┼──┼──┼──┼──┼──┼──┤
│⍒⌽│⌽ │⍋ │⍋⍒│⍒ │⍒⍒│⍋⌽│⊢ │
└──┴──┴──┴──┴──┴──┴──┴──┘
A permutation can be represented as an integer vector or as
a square boolean matrix with exactly one 1 in each row and each column.
Functions pm←⊢∘.=⍳∘≢ and mp←⍳∘1⍤1 transform from one to the other.
p x
6 3 2 1 5 4 0 96 84 59 5 19 47 36
pm p
0 0 0 0 0 0 1 x[p]
0 0 0 1 0 0 0 36 5 59 84 47 19 96
0 0 1 0 0 0 0
0 1 0 0 0 0 0 (pm p)+.×x
0 0 0 0 0 1 0 36 5 59 84 47 19 96
0 0 0 0 1 0 0
1 0 0 0 0 0 0
mp pm p
6 3 2 1 5 4 0
⊢ ⍋ ⍒ ⌽ on permutations produce permutation results.
They can be identified with ⊢ ⍉ ⊖⍉ ⊖
on square matrices.
(⊢ pm p) ≡ pm ⊢p
1
(⍉ pm p) ≡ pm ⍋p
1
(⊖⍉pm p) ≡ pm ⍒p
1
(⊖ pm p) ≡ pm ⌽p
1
Since ⊢ ⍉ ⊖⍉ ⊖ on matrices are transpositions of the square,
then so are ⊢ ⍋ ⍒ ⌽ on permutations.
The group table D8 is a compact presentation
of numerous identities involving ⊢ ⍋ ⍒ ⌽ on permutations
— D8[i;0] composed with D8[0;j] is D8[i;j] .
For example:
| i | j |
D8[i;0] | D8[0;j] |
D8[i;j] |
| 5 | 5 | ⍋ | ⍋ | ⊢ |
| 2 | 2 | ⍒⍒ | ⍒⍒ | ⊢ |
| 1 | 2 | ⍒ | ⍒⍒ | ⍋⌽ |
| 1 | 5 | ⍒ | ⍋ | ⌽ |
| 1 | 6 | ⍒ | ⍋⍒ | ⍋ |
That is, the 2 2 entry asserts that ⍒⍒⍒⍒p ←→ ⊢p ;
the 1 5 entry asserts that ⍒⍋p ←→ ⌽p ; and so on.
The veracity of these assertions can be checked
by (⍎¨D8,¨'p') ≡ ⍎¨(∘.,⍨0⌷D8),¨'p' ⊣ p←?⍨n .
Finally, per the previous section, (r D8) ≡ r ∘.{⍺[⍵]}⍨ ↓r D8 .
|
E. I←{(⍴⍵)⍴(≢⍺)↓i⊣i[i]←+\(≢⍺)>i←⍋⍺,,⍵}
|
| |
Interval index: ⍺ is a sorted (strictly ascending) vector; ⍺ I ⍵[i]
is the least j such that ⍺[j]
follows ⍵[i] in the ordering, or ≢⍺ if ⍵[i]
follows ¯1↑⍺ in the ordering or
if ⍺ is empty.
The function is named classify in
[35, §1.2]
and is a limited version of the I. primitive in J
[37].
t ,[¯0.5] ¯1.5 1 4 I t←¯2+⍳8
¯2 ¯1 0 1 2 3 4 5
0 1 1 2 2 2 3 3
¯1.5 1 4 I 2 2⍴5 3.1 4 ¯20
3 2
3 0
'aeiou' I 'deipnosophist'
1 2 3 4 3 4 4 4 4 2 3 4 4
The function can be expressed more concisely and more clearly by use of the merge operator, discussed in
[35,
37,
38]
and whimsically denoted by → :
{(⍴⍵)⍴(≢⍺)↓(+\i<≢⍺)(i→)i←⍋⍺,,⍵}
|
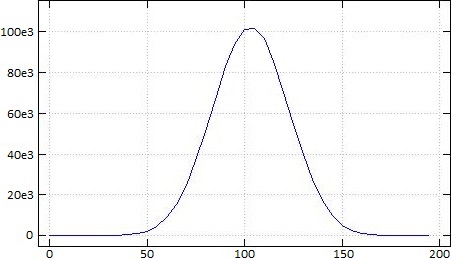
F. ¯1+{≢⍵}⌸(⍳41),(5×⍳40)I+⌿?10 1e6⍴21
|
| |
An illustration of the central limit theorem,
that the sum of independent random variables converges to the normal distribution
[37, I.].
t←¯1+{≢⍵}⌸(⍳41),(5×⍳40)I+⌿?10 1e6⍴21
⍴t
41
5 8⍴t
0 0 0 0 0 13 28 90
317 894 2095 4574 8671 15001 24338 36728
51254 66804 82787 93943 101045 101752 96510 85281
70418 54506 39802 27267 16964 9764 5031 2467
1059 422 136 32 6 1 0 0
t counts the number of occurrences
in the intervals with endpoints 5×⍳40 ,
of 1e6 samples
from the sum of ten repetitions of ?21 .
A plot of t :
The derived function {≢⍵}⌸x counts the number
of occurrences of each unique cell of x .
On 1-byte integers the computation takes only 1.4 times as
long as required for the apparently simpler problem ⌈/x .
Thinking about an obvious C implementation for {≢⍵}⌸x
leads to a non-obvious implementation for ⌈/x
[7, §16]
faster than
max=*x++; for(i=1;i<n;++i){if(max<*x)max=*x; ++x;}
|
The fine print. The exposition requires:
Dyalog APL Version 14.0 or later; ⎕io←0 ; ⎕ml←1 ; ]box on .
References
| [0] |
Iverson, K.E.,
A Programming Language,
Wiley, 1962-05.
|
| [1] |
Knuth, Donald E.,
Two Notes on Notation,
American Mathematical Monthly, Volume 99, Number 5, 1992-05-01.
|
| [2] |
Scholes, John,
Data-driven Conditionals,
Dyalog Blog, 2014-10-13.
|
| [3] |
Hui, Roger K.W., Phil Last, and John Scholes,
e-mail discussion,
2014-10-18 to -20.
|
| [4] |
Hui, Roger K.W., editor,
Ken Iverson Quotations and Anecdotes,
2014-10-10.
|
| [5] |
Hui, Roger K.W.,
On Average,
Vector, Volume 24, Number 2&3, 2010-08.
|
| [6] |
Azzarello, Arlene, editor,
APL QUOTE-QUAD: The Early Years,
APL Press, Palo Alto, 1982-11.
|
| [7] |
Hui, Roger K.W.,
Index-Of, A 30-Year Quest,
J Conference 2014, 2014-07-25.
|
| [8] |
Hui, Roger K.W.,
Dyalog Potential v14.0 Language Features, Dyalog User Conference, 2012-10-15.
|
| [9] |
Hui, Roger K.W.,
A Speed-Up Story,
Dyalog Blog, 2014-11-05.
|
| [10] |
Hui, Roger K.W.,
Rank & Friends,
Dyalog User Conference, 2013-10-22.
|
| [11] |
Smillie, Keith W.,
STATPACK: An APL Statistical Package,
University of Alberta, 1968.
|
| [12] |
Iverson, K.E.,
APL in Exposition,
IBM Corporation, 1972-01.
|
| [13] |
Perlis, Alan J.,
Almost
Perfect Artifacts Improve only in Small Ways: APL is more French than English,
APL78, 1978-03-29.
|
| [14] |
Hui, Roger K.W.,
An Amuse-Bouche from APL History,
2014-10-25.
|
| [15] |
Thomson, Norman,
Jottings 43: A Rippling Good Yarn!,
Vector, Volume 21, Number 3, 2005-05.
|
| [16] |
Scholes, John,
Ripple,
D-Function Workspaces, 2007-03-05.
|
| [17] |
OEIS,
Sequence A024222,
On-line Encyclopedia of Integer Sequences, 2014.
|
| [18] |
Hui, Roger K.W.,
Quicksort,
J Wiki Essay, 2005-09-28.
|
| [19] |
Hui, Roger K.W.,
Pascal’s Triangle,
J Wiki Essay, 2005-09-28.
|
| [20] |
Falkoff, A.D., and K.E. Iverson,
The APL\360 Terminal System,
Research Report RC-1922, IBM, 1967-10-16.
|
| [21] |
Hui, R.K.W., K.E. Iverson, E.E. McDonnell, and A.T. Whitney,
APL\?,
APL90, APL Quote Quad, Volume 20, Number 4, 1990-07.
|
| [22] |
Iverson, K.E.,
Elementary Functions: An Algorithmic Treatment,
Science Research Associates, Inc., 1966.
|
| [23] |
Falkoff, A.D. and K.E. Iverson,
APL\360 User’s Manual,
IBM Corporation, 1968-08.
|
| [24] |
Iverson, K.E.,
Algebra: An Algorithmic Treatment,
Addison-Wesley, 1972.
|
| [25] |
Iverson, K.E.,
Introducing APL to Teachers,
IBM Corporation, 1972-07.
|
| [26] |
Iverson, K.E.,
An Introduction to APL for Scientists and Engineers,
IBM Corporation, 1973-03.
|
| [27] |
Iverson, K.E.,
Elementary Analysis,
APL Press, 1976.
|
| [28] |
Iverson, K.E.,
Programming Style in APL,
1978 APL Users Meeting Proceedings, 1978-09-18.
|
| [29] |
Iverson, K.E.,
Notation as a Tool of Thought,
Communications of the ACM, Volume 23, Number 8, 1980-08.
|
| [30] |
Iverson, K.E.,
A Dictionary of APL,
APL Quote Quad, Volume 18, Number 1, 1987-09.
|
| [31] |
Hui, Roger K.W.,
Fibonacci Sequence,
J Wiki Essay, 2005-09-26.
|
| [32] |
Hui, Roger K.W.,
Newton’s Method,
J Wiki Essay, 2005-10-15.
|
| [33] |
Hui, Roger K.W.,
Inner Product — An Old/New Problem,
2009-06-07.
|
| [34] |
Hui, Roger K.W., editor,
APL Quotations and Anecdotes,
2014.
|
| [35] |
Hui, Roger K.W.,
Some Uses of { and },
APL87, APL Quote Quad, Volume 17, Number 4, 1987-05.
|
| [36] |
Hui, Roger K.W.,
Symmetries of the Square,
J Wiki Essay, 2005-11-07.
|
| [37] |
Hui, Roger K.W., and K.E. Iverson,
J Introduction and Dictionary,
2011-05-03.
|
| [38] |
Scholes, John,
Merge,
D-Function Workspaces, 2014.
|
| created: | 2014-10-11 20:00 |
| updated: | 2018-06-22 20:30 |
|