Notation as a Tool of Thought
Kenneth E. Iverson
IBM Thomas J. Watson Research Center
The importance of nomenclature, notation, and language as tools of thought has long been recognized. In chemistry and in botany, for example, the establishment of systems of nomenclature by Lavoisier and Linnaeus did much to stimulate and to channel later investigation. Concerning language, George Boole in his Laws of Thought [1, p.24] asserted “That language is an instrument of human reason, and not merely a medium for the expression of thought, is a truth generally admitted.”
Mathematical notation provides perhaps the best-known and best-developed example of language used consciously as a tool of thought. Recognition of the important role of notation in mathematics is clear from the quotations from mathematicians given in Cajori’s A History of Mathematical Notations [2, pp.332,331]. They are well worth reading in full, but the following excerpts suggest the tone:
| By relieving the brain of all unnecessary work, a good notation sets it free to concentrate on more advanced problems, and in effect increases the mental power of the race. | |
| A.N. Whitehead |
| The quantity of meaning compressed into small space by algebraic signs, is another circumstance that facilitates the reasonings we are accustomed to carry on by their aid. | |
| Charles Babbage |
Nevertheless, mathematical notation has serious deficiencies. In particular, it lacks universality, and must be interpreted differently according to the topic, according to the author, and even according to the immediate context. Programming languages, because they were designed for the purpose of directing computers, offer important advantages as tools of thought. Not only are they universal (general-purpose), but they are also executable and unambiguous. Executability makes it possible to use computers to perform extensive experiments on ideas expressed in a programming language, and the lack of ambiguity makes possible precise thought experiments. In other respects, however, most programming languages are decidedly inferior to mathematical notation and are little used as tools of thought in ways that would be considered significant by, say, an applied mathematician.
The thesis of the present paper is that the advantages of executability and universality found in programming languages can be effectively combined, in a single coherent language, with the advantages offered by mathematical notation. It is developed in four stages:
| (a) | Section 1 identifies salient characteristics of mathematical notation and uses simple problems to illustrate how these characteristics may be provided in an executable notation. | |
| (b) | Sections 2 and 3 continue this illustration by deeper treatment of a set of topics chosen for their general interest and utility. Section 2 concerns polynomials, and Section 3 concerns transformations between representations of functions relevant to a number of topics, including permutations and directed graphs. Although these topics might be characterized as mathematical, they are directly relevant to computer programming, and their relevance will increase as programming continues to develop into a legitimate mathematical discipline. | |
| (c) | Section 4 provides examples of identities and formal proofs. Many of these formal proofs concern identities established informally and used in preceeding sections. | |
| (d) | The concluding section provides some general comparisons with mathematical notation, references to treatments of other topics, and discussion of the problem of introducing notation in context. |
The executable language to be used is APL, a general purpose language which originated in an attempt to provide clear and precise expression in writing and teaching, and which was implemented as a programming language only after several years of use and development [3].
Although many readers will be unfamiliar with APL, I have chosen not to provide a separate introduction to it, but rather to introduce it in context as needed. Mathematical notation is always introduced in this way rather than being taught, as programming languages commonly are, in a separate course. Notation suited as a tool of thought in any topic should permit easy introduction in the context of that topic; one advantage of introducing APL in context here is that the reader may assess the relative difficulty of such introduction.
However, introduction in context is incompatible with complete discussion of all nuances of each bit of notation, and the reader must be prepared to either extend the definitions in obvious and systematic ways as required in later uses, or to consult a reference work. All of the notation used here is summarized in Appendix A, and is covered fully in pages 24-60 of APL Language [4].
Readers having access to some machine embodiment of APL may wish to translate the function definitions given here in direct definition form [5, p.10] (using ⍺ and ⍵ to represent the left and right arguments) to the canonical form required for execution. A function for performing this translation automatically is given in Appendix B.
1. Important Characteristics of Notation
In addition to the executability and universality emphasized in the introduction, a good notation should embody characteristics familiar to any user of mathematical notation:
- Ease of expressing constructs arising in problems.
- Suggestivity.
- Ability to subordinate detail.
- Economy.
- Amenability to formal proofs.
The foregoing is not intended as an exhaustive list, but will be used to shape the subsequent discussion.
Unambiguous executability of the notation introduced remains important, and will be emphasized by displaying below an expression the explicit result produced by it. To maintain the distinction between expressions and results, the expressions will be indented as they automatically are on APL computers. For example, the integer function denoted by ⍳ produces a vector of the first n integers when applied to the argument n , and the sum reduction denoted by +/ produces the sum of the elements of its vector argument, and will be shown as follows:
⍳5
1 2 3 4 5
+/⍳5
15
We will use one non-executable bit of notation: the symbol ←→ appearing between two expressions asserts their equivalance.
1.1 Ease of Expressing Constructs Arising in Problems
If it is to be effective as a tool of thought, a notation must allow convenient expression not only of notions arising directly from a problem, but also of those arising in subsequent analysis, generalization, and specialization.
Consider, for example, the crystal structure illustrated by Figure 1, in which successive layers of atoms lie not directly on top of one another, but lie “close-packed” between those below them. The numbers of atoms in successive rows from the top in Figure 1 are therefore given by ⍳5 , and the total number is given by +/⍳5 .
The three-dimensional structure of such a crystal is also close-packed; the atoms in the plane lying above Figure 1 would lie between the atoms in the plane below it, and would have a base row of four atoms. The complete three-dimensional structure corresponding to Figure 1 is therefore a tetrahedron whose planes have bases of lengths 1 , 2 , 3 , 4 , and 5 . The numbers in successive planes are therefore the partial sums of the vector ⍳5 , that is, the sum of the first element, the sum of the first two elements, etc. Such partial sums of a vector v are denoted by +\v , the function +\ being called sum scan. Thus:
+\⍳5
1 3 6 10 15
+/+\⍳5
35
The final expression gives the total number of atoms in the tetrahedron.
The sum +/⍳5 can be represented graphically in other ways, such as shown on the left of Figure 2. Combined with the inverted pattern on the right, this representation suggests that the sum may be simply related to the number of units in a rectangle, that is, to a product.
The lengths of the rows of the figure formed by pushing together the two parts of Figure 2 are given by adding the vector ⍳5 to the same vector reversed. Thus:
⍳6
1 2 3 4 5 6
⍳5
1 2 3 4 5
⌽⍳5
5 4 3 2 1
(⍳5)+(⌽⍳5)
6 6 6 6 6
Fig. 1. Fig. 2.
○ ⎕ ⎕⎕⎕⎕⎕
○ ○ ⎕⎕ ⎕⎕⎕⎕
○ ○ ○ ⎕⎕⎕ ⎕⎕⎕
○ ○ ○ ○ ⎕⎕⎕⎕ ⎕⎕
○ ○ ○ ○ ○ ⎕⎕⎕⎕⎕ ⎕
This pattern of 5 repetitions of 6 may be expressed as 5⍴6 , and we have:
5⍴6
6 6 6 6 6
+/5⍴6
30
6×5
30
The fact that +/5⍴6 ←→ 6×5 follows from the definition of multiplication as repeated addition.
The foregoing suggests that +/⍳5 ←→ (6×5)÷2 , and, more generally, that:
| +/⍳n ←→ ((n+1)×n)÷2 | A.1 |
1.2 Suggestivity
A notation will be said to be suggestive if the forms of the expressions arising in one set of problems suggest related expressions which find application in other problems. We will now consider related uses of the functions introduced thus far, namely:
⍳ ⌽ ⍴ +/ +\
The example:
5⍴2
2 2 2 2 2
×/5⍴2
32
suggests that ×/m⍴n ←→ n*m , where * represents the power function. The similiarity between the definitions of power in terms of times, and of times in terms of plus may therefore be exhibited as follows:
+/m⍴n ←→ n×m
×/m⍴n ←→ n*m
Similar expressions for partial sums and partial products may be developed as follows:
×\5⍴2
2 4 8 16 32
2*⍳5
2 4 8 16 32
+\m⍴n ←→ n×⍳m
×\m⍴n ←→ n*⍳m
Because they can be represented by a triangle as in Figure 1, the sums +\⍳5 are called triangular numbers. They are a special case of the figurate numbers obtained by repeated applications of sum scan, beginning either with +\⍳n , or with +\n⍴1 . Thus:
5⍴1 +\+\5⍴1
1 1 1 1 1 1 3 6 10 15
+\5⍴1 +\+\+\5⍴1
1 2 3 4 5 1 4 10 20 35
Replacing sums over the successive integers by products yields the factorials as follows:
⍳5
1 2 3 4 5
×/⍳5 ×\⍳5
120 1 2 6 24 120
!5 !⍳5
120 1 2 6 24 120
Part of the suggestive power of a language resides in the ability to represent identities in brief, general, and easily remembered forms. We will illustrate this by expressing dualities between functions in a form which embraces DeMorgan’s laws, multiplication by the use of logarithms, and other less familiar identities.
If v is a vector of positive numbers, then the product ×/v may be obtained by taking the natural logarithms of each element of v (denoted by ⍟v), summing them (+/⍟v), and applying the exponential function (*+/⍟v). Thus:
×/v ←→ *+/⍟v
Since the exponential function * is the inverse of the natural logarithm ⍟ , the general form suggested by the right side of the identity is:
ig f/g v
where ig is the function inverse to g .
Using ∧ and ∨ to denote the functions and and or, and ~ to denote the self-inverse function of logical negation, we may express DeMorgan’s laws for an arbitrary number of elements by:
∧/b ←→ ~∨/~b
∨/b ←→ ~^/~b
The elements of b are, of course, restricted to the boolean values 0 and 1 . Using the relation symbols to denote functions (for example, x<y yields 1 if x is less than y and 0 otherwise) we can express further dualities, such as:
≠/b ←→ ~=/~b
=/b ←→ ~≠/~b
Finally, using ⌈ and ⌊ to denote the maximum and minimum functions, we can express dualities which involve arithmetic negation:
⌈/v ←→ -⌊/-v
⌊/v ←→ -⌈/-v
It may also be noted that scan (f\) may replace reduction (f/) in any of the foregoing dualities.
1.3 Subordination of Detail
As Babbage remarked in the passage cited by Cajori, brevity facilitates reasoning. Brevity is achieved by subordinating detail, and we will here consider three important ways of doing this: the use of arrays, the assignment of names to functions and variables, and the use of operators.
We have already seen examples of the brevity provided by one-dimensional arrays (vectors) in the treatment of duality, and further subordination is provided by matrices and other arrays of higher rank, since functions defined on vectors are extended systematically to arrays of higher rank.
In particular, one may specify the axis to which a function applies. For example, ⌽[1]m acts along the first axis of a matrix m to reverse each of the columns, and ⌽[2]m reverses each row; m,[1]n catenates columns (placing m above n), and m,[2]n catenates rows; and +/[1]m sums columns and +/[2]m sums rows. If no axis is specified, the function applies along the last axis. Thus +/m sums rows. Finally, reduction and scan along the first axis may be denoted by the symbols ⌿ and ⍀ .
Two uses of names may be distinguished: constant names which have fixed referents are used for entities of very general utility, and ad hoc names are assigned (by means of the symbol ←) to quantities of interest in a narrower context. For example, the constant (name) 144 has a fixed referent, but the names crate , layer , and row assigned by the expressions
crate ← 144
layer ← crate÷8
row ← layer÷3
are ad hoc, or variable names.
Constant names for vectors are also provided,
as in
Analogous distinctions are made in the names of functions. Constant names such as + , × , and * are assigned to so-called primitive functions of general utility. The detailed definitions, such as +/m⍴n for n×m and */mc for n*m , are subordinated by the constant names × and * .
Less familiar examples of constant function names are provided by the comma which catenates its arguments as illustrated by:
(⍳5),(⌽⍳5) ←→ 1 2 3 4 5 5 4 3 2 1
and by the base-representation function ⊤ , which produces a representation of its right argument in the radix specified by its left argument. For example:
2 2 2 ⊤ 3 ←→ 0 1 1
2 2 2 ⊤ 4 ←→ 1 0 0
bn←2 2 2 ⊤ 0 1 2 3 4 5 6 7
bn
0 0 0 0 1 1 1 1
0 0 1 1 0 0 1 1
0 1 0 1 0 1 0 1
bn,⌽bn
0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 0
0 0 1 1 0 0 1 1 1 1 0 0 1 1 0 0
0 1 0 1 0 1 0 1 1 0 1 0 1 0 1 0
The matrix bn is an important one, since it can be viewed in several ways. In addition to representing the binary numbers, the columns represent all subsets of a set of three elements, as well as the entries in a truth table for three boolean arguments. The general expression for n elements is easily seen to be (n⍴2)⊤(⍳2*n)-1 , and we may wish to assign an ad hoc name to this function. Using the direct definition form (Appendix B), the name T is assigned to this function as follows:
| T:(⍵⍴2)⊤(⍳2*⍵)-1 | A.2 |
The symbol ⍵ represents the argument of the function; in the case of two arguments the left is represented by ⍺ . Following such a definition of the function T , the expression T 3 yields the boolean matrix bn shown above.
Three expressions, separated by colons, are also used to define a function as follows: the middle expression is executed first; if its value is zero the first expression is executed, if not, the last expression is executed. This form is convenient for recursive definitions, in which the function is used in its own definition. For example, a function which produces binomial coefficients of an order specified by its argument may be defined recursively as follows:
| bc:(x,0)+(0,x←bc ⍵-1):⍵=0:1 | A.3 |
Thus bc 0 ←→ 1 and bc 1 ←→ 1 1 and bc 4 ←→ 1 4 6 4 1 .
The term operator, used in the strict sense defined in mathematics rather than loosely as a synonym for function, refers to an entity which applies to functions to produce functions; an example is the derivative operator.
We have already met two operators, reduction, and scan, denoted by / and \ , and seen how they contribute to brevity by applying to different functions to produce families of related functions such as +/ and ×/ and ^/ . We will now illustrate the notion further by introducing the inner product operator denoted by a period. A function (such as +/) produced by an operator will be called a derived function.
If p and q are two vectors, then the inner product +.× is defined by:
p+.×q ←→ +/p×q
and analogous definitions hold for function pairs other than + and × . For example:
p←2 3 5
q←2 1 2
p+.×q
17
p×.*q
300
p⌊.+q
4
Each of the foregoing expressions has at least one useful interpretation: p+.×q is the total cost of order quantities q for items whose prices are given by p ; because p is a vector of primes, p×.*q is the number whose prime decomposition is given by the exponents q ; and if p gives distances from a source to transhipment points and q gives distances from the transhipment points to the destination, then p⌊.+q gives the minimum distance possible.
The function +.× is equivalent to the inner product or dot product of mathematics, and is extended to matrices as in mathematics. Other cases such as ×.* are extended analogously. For example, if T is the function defined by A.2, then:
T 3
0 0 0 0 1 1 1 1
0 0 1 1 0 0 1 1
0 1 0 1 0 1 0 1
p+.×T 3 p×.*T 3
0 5 3 8 2 7 5 10 1 5 3 15 2 10 6 30
These examples bring out an important point: if b is boolean, then p+.×b produces sums over subsets of p specified by 1’s in b , and p×.*b produces products over subsets.
The phrase ∘.× is a special use of the inner product operator to produce a derived function which yields products of each element of its left argument with each element of its right. For example:
2 3 5∘.×⍳5
2 4 6 8 10
3 6 9 12 15
5 10 15 20 25
The function ∘.× is called outer product, as it is in tensor analysis, and functions such as ∘.+ and ∘.* and ∘.< are defined analogously, producing “function tables” for the particular functions. For example:
d←0 1 2 3
d∘.⌈d d∘.≥d d∘.!d
0 1 2 3 1 0 0 0 1 1 1 1
1 1 2 3 1 1 0 0 0 1 2 3
2 2 2 3 1 1 1 0 0 0 1 3
3 3 3 3 1 1 1 1 0 0 0 1
The symbol ! denotes the binomial coefficient function, and the table d∘.!d is seen to contain Pascal’s triangle with its apex at the left; if extended to negative arguments (as with d←¯3 ¯2 ¯1 0 1 2 3) it will be seen to contain the triangular and higher-order figurate numbers as well. This extension to negative arguments is interesting for other functions as well. For example, the table d∘.×d consists of four quadrants separated by a row and a column of zeros, the quadrants showing clearly the rule of signs for multiplication.
Patterns in these function tables exhibit other properties of the functions, allowing brief statements of proofs by exhaustion. For example, commutativity appears as a symmetry about the diagonal. More precisely, if the result of the transpose function ⍉ (which reverses the order of the axes of its argument) applied to a table t←d∘.f d agrees with t , then the function f is commutative on the domain. For example, t=⍉t←d∘.⌈d produces a table of 1’s because ⌈ is commutative.
Corresponding tests of associativity require rank 3 tables of the form d∘.f(d∘.f d) and (d∘.f d)∘.f d . For example:
d←0 1
d∘.∧(d∘.∧d) (d∘.∧d)∘.∧d d∘.≤(d∘.≤d) (d∘.≤d)∘.≤d
0 0 0 0 1 1 0 1
0 0 0 0 1 1 0 1
0 0 0 0 1 1 1 1
0 1 0 1 0 1 0 1
1.4 Economy
The utility of a language as a tool of thought increases with the range of topics it can treat, but decreases with the amount of vocabulary and the complexity of grammatical rules which the user must keep in mind. Economy of notation is therefore important.
Economy requires that a large number of ideas be expressible in terms of a relatively small vocabulary. A fundamental scheme for achieving this is the introduction of grammatical rules by which meaningful phrases and sentences can be constructed by combining elements of the vocabulary.
This scheme may be illustrated by the first example treated — the relatively simple and widely useful notion of the sum of the first n integers was not introduced as a primitive, but as a phrase constructed from two more generally useful notions, the function ⍳ for the production of a vector of integers, and the function +/ for the summation of the elements of a vector. Moreover, the derived function +/ is itself a phrase, summation being a derived function constructed from the more general notion of the reduction operator applied to a particular function.
Economy is also achieved by generality in the functions introduced. For example, the definition of the factorial function denoted by ! is not restricted to integers, and the gamma function of x may therefore be written as !x-1 . Similiarly, the relations defined on all real arguments provide several important logical functions when applied to boolean arguments: exclusive-or (≠), material implication (≤), and equivalence (=).
The economy achieved for the matters treated thus far can be assessed by recalling the vocabulary introduced:
⍳ ⍴ ⌽ ⊤ ,
/ \ .
+-×÷*⍟!⌈⌊⍉
∨∧~<≤=≥>≠
The five functions and three operators listed in the first two rows are of primary interest, the remaining familiar functions having been introduced to illustrate the versatility of the operators.
A significant economy of symbols, as opposed to economy of functions, is attained by allowing any symbol to represent both a monadic function (i.e. a function of one argument) and a dyadic function, in the same manner that the minus sign is commonly used for both subtraction and negation. Because the two functions represented may, as in the case of the minus sign, be related, the burden of remembering symbols is eased.
For example, x*y and *y represent power and exponential, x⍟y and ⍟y represent base x logarithm and natural logarithm, x÷y and ÷y represent division and reciprocal, and x!y and !y represent the binomial coefficient function and the factorial (that is, x!y←→(!y)÷(!x)×(!y-x)). The symbol ⍴ used for the dyadic function of replication also represents a monadic function which gives the shape of the argument (that is, x←→⍴x⍴y), the symbol ⌽ used for the monadic reversal function also represents the dyadic rotate function exemplified by 2⌽⍳5←→3 4 5 1 2 , and by ¯2⌽⍳5←→4 5 1 2 3 , and finally, the comma represents not only catenation, but also the monadic ravel, which produces a vector of the elements of its argument in “row-major” order. For example:
T 2 ,T 2
0 0 1 1 0 0 1 1 0 1 0 1
0 1 0 1
Simplicity of the grammatical rules of a notation is also important. Because the rules used thus far have been those familiar in mathematical notation, they have not been made explicit, but two simplifications in the order of execution should be remarked:
| (1) | All functions are treated alike, and there are no rules of precedence such as × being executed before + . | |
| (2) | The rule that the right argument of a monadic function is the value of the entire expression to its right, implicit in the order of execution of an expression such as sin log !n , is extended to dyadic functions. |
The second rule has certain useful consequences in reduction and scan. Since f/v is equivalent to placing the function f between the elements of v , the expression -/v gives the alternating sum of the elements of v , and ÷/v gives the alternating product. Moreover, if b is a boolean vector, then <\b “isolates” the first 1 in b , since all elements following it become 0. For example.
<\0 0 1 1 0 1 1 ←→ 0 0 1 0 0 0 0
Syntactic rules are further simplified by adopting a single form for all dyadic functions, which appear between their arguments, and for all monadic functions, which appear before their arguments. This contrasts with the variety of rules in mathematics. For example, the symbols for the monadic functions of negation, factorial, and magnitude precede, follow, and surround their arguments, respectively. Dyadic functions show even more variety.
1.5 Amenability to Formal Proofs
The importance of formal proofs and derivations is clear from their role in mathematics. Section 4 is largely devoted to formal proofs, and we will limit the discussion here to the introduction of the forms used.
Proof by exhaustion consists of exhaustively examining all of a finite number of special cases. Such exhaustion can often be simply expressed by applying some outer product to arguments which include all elements of the relevant domain. For example, if d←0 1 , then d∘.∧d gives all cases of application of the and function. Moreover, DeMorgan’s law can be proved exhaustively by comparing each element of the matrix d∘.∧d with each element of ~(~d)∘.∨(~d) as follows:
d∘.∧d ~(~d)∘.∨(~d)
0 0 0 0
0 1 0 1
(d∘.∧d)=(~(~d)∘.∨(~d))
1 1
1 1
∧/,(d∘.∧d)=(~(~d)∘.∨(~d))
1
Questions of associativity can be addressed similarly, the following expressions showing the associativity of and and the non-associativity of not-and:
∧/,((d∘.∧d)∘.∧d)=(d∘.∧(d∘.∧d))
1
∧/,((d∘.⍲d)∘.⍲d)=(d∘.⍲(d∘.⍲d))
0
A proof by a sequence of identities is presented by listing a sequence of expressions, annotating each expression with the supporting evidence for its equivalence with its predecessor. For example, a formal proof of the identity A.1 suggested by the first example treated would be presented as follows:
| +/⍳n | |
| +/⌽⍳n | + is associative and commutative |
| ((+/⍳n)+(+/⌽⍳n))÷2 | (x+x)÷2←→x |
| (+/((⍳n)+(⌽⍳n)))÷2 | + is associative and commutative |
| (+/((n+1)⍴n))÷2 | Lemma |
| ((n+1)×n)÷2 | Definition of × |
The fourth annotation above concerns an identity which, after observation of the pattern in the special case (⍳5)+(⌽⍳5) , might be considered obvious or might be considered worthy of formal proof in a separate lemma.
Inductive proofs proceed in two steps: 1) some identity (called the induction hypothesis) is assumed true for a fixed integer value of some parameter n and this assumption is used to prove that the identity also holds for the value n+1 , and 2) the identity is shown to hold for some integer value k . The conclusion is that the identity holds for all integer values of n which equal or exceed k .
Recursive definitions often provide convenient bases for inductive proofs. As an example we will use the recursive definition of the binomial coefficient function bc given by A.3 in an inductive proof showing that the sum of the binomial coefficients of order n is 2*n . As the induction hypothesis we assume the identity:
+/bc n ←→ 2*n
and proceed as follows:
| +/bc n+1 | |
| +/(x,0)+(0,x←bc n) | A.3 |
| (+/x,0)+(+/0,x) | + is associative and commutative |
| (+/x)+(+/x) | 0+y←→y |
| 2×+/x | y+y←→2×y |
| 2×+/bc n | Definition of x |
| 2×2*n | Inductive hypothesis |
| 2*n+1 | Property of Power (*) |
It remains to show that the induction hypothesis is true for some integer value of n . From the recursive definition A.3, the value of BC 0 is the value of the rightmost expression, namely 1 . Consequently, +/bc 0 is 1 , and therefore equals 2*0 .
We will conclude with a proof that DeMorgan’s law for scalar arguments, represented by:
| a^b ←→ ~(~a)∨(~b) | A.4 |
and proved by exhaustion, can indeed be extended to vectors of arbitrary length as indicated earlier by the putative identity:
| ^/v ←→ ~∨/~v | A.5 |
As the induction hypothesis we will assume that A.5 is true for vectors of length (⍴v)-1 .
We will first give formal recursive definitions of the derived functions and-reduction and or-reduction (^/ and ∨/), using two new primitives, indexing, and drop. Indexing is denoted by an expression of the form x[i] , where i is a single index or array of indices of the vector x . For example, if x←2 3 5 7 , then x[2] is 3 , and x[2 1] is 3 2 . Drop is denoted by k↓x and is defined to drop |k (i.e., the magnitude of k) elements from x , from the head if k>0 and from the tail if k<0 . For example, 2↓x is 5 7 and ¯2↓x is 2 3 . The take function (to be used later) is denoted by ↑ and is defined analogously. For example, 3↑x is 2 3 5 and ¯3↑x is 3 5 7 .
The following functions provide formal definitions of and-reduction and or-reduction:
| andred:⍵[1]^andred 1↓⍵:0=⍴⍵:1 | A.6 |
| orred :⍵[1]∨ orred 1↓⍵:0=⍴⍵:0 | A.7 |
The inductive proof of A.5 proceeds as follows:
| ^/v | |
| (v[1])^(^/1↓v) | A.6 |
| ~(~v[1])∨(~^/1↓v) | A.4 |
| ~(~v[1])∨(~~∨/~1↓v) | A.5 |
| ~(~v[1])∨(∨/~1↓v) | ~~x←→x |
| ~∨/(~v[1]),(~1↓v) | A.7 |
| ~∨/~(v[1]),(1↓v) | ∨ distributes over , |
| ~∨/~v | Definition of , (catenation) |
2. Polynomials
If c is a vector of coefficients and x is a scalar, then the polynomial in x with coefficients c may be written simply as +/c×x*¯1+⍳⍴c , or +/(x*¯1+⍳⍴c)×c , or (x*¯1+⍳⍴c)+.×c . However, to apply to a non-scalar array of arguments x , the power function * should be replaced by the power table ∘.* as shown in the following definition of the polynomial function:
| P:(⍵∘.*¯1+⍳⍴⍺)+.×⍺ | B.1 |
For example, 1 3 3 1 P 0 1 2 3 4 5 ←→ 1 8 27 64 125 . If ⍴⍺ is replaced by 1↑⍴⍺ , then the function applies also to matrices and higher dimensional arrays of sets of coefficients representing (along the leading axis of ⍺) collections of coefficients of different polynomials.
This definition shows clearly that the polynomial is a linear function of the coefficient vector. Moreover, if ⍺ and ⍵ are vectors of the same shape, then the pre-multiplier ⍵∘.*¯1+⍳⍴⍺ is the Vandermonde matrix of ⍵ and is therefore invertible if the elements of ⍵ are distinct. Hence if c and x are vectors of the same shape, and if y←c P x , then the inverse (curve-fitting) problem is clearly solved by applying the matrix inverse function ⌹ to the Vandermonde matrix and using the identity:
c ←→ (⌹x∘.*¯1+⍳⍴x)+.×y
2.1 Products of Polynomials
The “product of two polynomials b and c” is commonly taken to mean the coefficient vector d such that:
d P x ←→ (b P x)×(c P x)
It is well-known that d can be computed by taking products over all pairs of elements from b and c and summing over subsets of these products associated with the same exponent in the result. These products occur in the function table b∘.×c , and it is easy to show informally that the powers of x associated with the elements of b∘.×c are given by the addition table e←(¯1+⍳⍴b)∘.+(¯1+⍳⍴c) . For example:
x←2
b←3 1 2 3
c←2 0 3
e←(¯1+⍳⍴b)∘.+(¯1+⍳⍴c)
b∘.×c e x×e
6 0 9 0 1 2 0 2 4
2 0 3 1 2 3 2 4 6
4 0 6 2 3 4 4 6 8
6 0 9 3 4 5 6 8 10
+/,(b∘.×c)×x*e
518
(b P x)×(c P x)
518
The foregoing suggests the following identity, which will be established formally in Section 4:
| (b P x)×(c P x) ←→ +/,(b∘.×c)×x*(¯1+⍳⍴b)∘.+(¯1+⍳⍴c) | B.2 |
Moreover, the pattern of the exponent table e shows that elements of b∘.×c lying on diagonals are associated with the same power, and that the coefficient vector of the product polynomial is therefore given by sums over these diagonals. The table b∘.×c therefore provides an excellent organization for the manual computation of products of polynomials. In the present example these sums give the vector d←6 2 13 9 6 9 , and d P x may be seen to equal (b P x)×(c P x) .
Sums over the required diagonals of b∘.×c can also be obtained by bordering it by zeros, skewing the result by rotating successive rows by successive integers, and then summing the columns. We thus obtain a definition for the polynomial product function as follows:
pp:+⌿(1-⍳⍴⍺)⌽⍺∘.×⍵,1↓0×⍺
We will now develop an alternative method based upon the simple observation that if b pp c produces the product of polynomials b and c , then pp is linear in both of its arguments. Consequently,
pp:⍺+.×a+.×⍵
where a is an array to be determined. a must be of rank 3 , and must depend on the exponents of the left argument (¯1+⍳⍴⍺) , of the result (¯1+⍳⍴1↓⍺,⍵) , and of the right argument. The “deficiencies” of the right exponent are given by the difference table (⍳⍴1↓⍺,⍵)∘.-⍳⍴⍵ , and comparison of these values with the left exponents yields a . Thus
a←(¯1+⍳⍴⍺)∘.=(⍳⍴1↓⍺,⍵)∘.-⍳⍴⍵
and
pp:⍺+.×((¯1+⍳⍴⍺)∘.=(⍳⍴1↓⍺,⍵)∘.-⍳⍴⍵)+.×⍵
Since ⍺+.×a is a matrix, this formulation suggests that if d←b pp c , then c might be obtained from d by pre-multiplying it by the inverse matrix (⌹b+.×a) , thus providing division of polynomials. Since b+.×a is not square (having more rows than columns), this will not work, but by replacing m←b+.×a by either its leading square part (2⍴⌊/⍴m)↑m , or by its trailing square part (-2⍴⌊/⍴m)↑m , one obtains two results, one corresponding to division with low-order remainder terms, and the other to division with high-order remainder terms.
2.2 Derivative of a Polynomial
Since the derivative of x*n is n×x*n-1 , we may use the rules for the derivative of a sum of functions and of a product of a function with a constant, to show that the derivative of the polynomial c P x is the polynomial (1↓cׯ1+⍳⍴c) P x . Using this result it is clear that the integral is the polynomial (a,c÷⍳⍴c) P x , where a is an arbitrary scalar constant. The expression 1⌽cׯ1+⍳⍴c also yields the coefficients of the derivative, but as a vector of the same shape as c and having a final zero element.
2.3 Derivative of a Polynomial with Respect to Its Roots
If r is a vector of three elements, then the derivatives of the polynomial ×/x-r with respect to each of its three roots are -(x-r[2])×(x-r[3]) , and -(x-r[1])×(x-r[3]) , and -(x-r[1])×(x-r[2]) . More generally, the derivative of ×/x-r with respect to r[j] is simply -(x-r)×.*j≠⍳⍴r , and the vector of derivatives with respect to each of the roots is -(x-r)×.*i∘.≠i←⍳⍴r .
The expression ×/x-r for a polynomial with roots r applies only to a scalar x , the more general expression being ×/x∘.-r . Consequently, the general expression for the matrix of derivatives (of the polynomial evaluated at x[i] with respect to root r[j]) is given by:
| -(x∘.-r)×.*i∘.≠i←⍳⍴r | B.3 |
2.4 Expansion of a Polynomial
Binomial expansion concerns the development of an identity in the form of a polynomial in x for the expression (x+y)*n . For the special case of y=1 we have the well-known expression in terms of the binomial coefficients of order n :
(x+1)*n ←→ ((0,⍳n)!n)P x
By extension we speak of the expansion of a polynomial as a matter of determining coefficients d such that:
c P x+y ←→ d P x
The coefficients d are, in general, functions of y . If y=1 they again depend only on binomial coefficients, but in this case on the several binomial coefficients of various orders, specifically on the matrix j∘.!j←¯1+⍳⍴c .
For example, if c←3 1 2 4 , and c P x+1←→d P x , then d depends on the matrix:
0 1 2 3 ∘.! 0 1 2 3
1 1 1 1
0 1 2 3
0 0 1 3
0 0 0 1
and d must clearly be a weighted sum of the columns, the weights being the elements of c . Thus:
d←(j∘.!j←¯1+⍳⍴c)+.×c
Jotting down the matrix of coefficients and performing the indicated matrix product provides a quick and reliable way to organize the otherwise messy manual calculation of expansions.
If b is the appropriate matrix of binomial coefficients, then d←b+.×c , and the expansion function is clearly linear in the coefficients c . Moreover, expansion for y=¯1 must be given by the inverse matrix ⌹b , which will be seen to contain the alternating binomial coefficients. Finally, since:
c P x+(k+1) ←→ c P (x+k)+1 ←→ (b+.×c) P (x+k)
it follows that the expansion for positive integer values of y must be given by products of the form:
b+.×b+.×b+.×b+.×c
where the b occurs y times.
Because +.× is associative, the foregoing can be written as m+.×c , where m is the product of y occurrences of b . It is interesting to examine the successive powers of b , computed either manually or by machine execution of the following inner product power function:
ipp:⍺+.×⍺ ipp ⍵-1:⍵=0:j∘.!j←¯1+⍳⍴⍺
Comparison of b ipp k with b for a few values of k shows an obvious pattern which may be expressed as:
b ipp k ←→ b×k*0⌈-j∘.-j←¯1+⍳1↑⍴b
The interesting thing is that the right side of this identity is meaningful for non-integer values of k , and, in fact, provides the desired expression for the general expansion c P x+y :
| c P(x+y) ←→ (((j∘.!j)×y*0⌈-j∘.-j←¯1+⍳⍴c)+.×c)P x | B.4 |
The right side of B.4 is of the form (m+.×c)P x , where m itself is of the form bxy*e and can be displayed informally (for the case 4=⍴c) as follows:
1 1 1 1 0 1 2 3
0 1 2 3 0 0 1 2
0 0 1 3 ×y* 0 0 0 1
0 0 0 1 0 0 0 0
Since y*k multiplies the single-diagonal matrix b×(k=e) , the expression for m can also be written as the inner product (y*j)+.×t , where t is a rank 3 array; whose kth plane is the matrix b×(k=e)). Such a rank three array can be formed from an upper triangular matrix m by making a rank 3 array whose first plane is m (that is, (1=⍳1↑⍴m)∘.×m) and rotating it along the first axis by the matrix j∘-j , whose kth superdiagonal has the value -k . Thus:
| ds←(i∘.-i)⌽[1](1=i←⍳1↑⍴⍵)∘.×⍵ | B.5 |
ds k∘.!k←¯1+⍳3
1 0 0
0 1 0
0 0 1
0 1 0
0 0 2
0 0 0
0 0 1
0 0 0
0 0 0
Substituting these results in B.4 and using the associativity of +.x , we have the following identity for the expansion of a polynomial, valid for non-integer as well as integer values of r :
| c P x+y ←→ ((y*j)+.×(ds j∘.!j←¯1+⍳⍴c)+.×c)P x | B.6 |
For example:
y←3
c←3 1 4 2
m←(y*j)+.×ds j∘.!j←¯1+⍳⍴c
m
1 3 9 27
0 1 6 27
0 0 1 9
0 0 0 1
m+.×c
96 79 22 2
(m+.×c) P x←2
358
c P x+y
358
3. Representations
The subjects of mathematical analysis and computation can be represented in a variety of ways, and each representation may possess particular advantages. For example, a positive integer n may be represented simply by n check-marks; less simply, but more compactly, in Roman numerals; even less simply, but more conveniently for the performance of addition and multiplication, in the decimal system; and less familiarly, but more conveniently for the computation of the least common multiple and the greatest common divisor, in the prime decomposition scheme to be discussed here.
Graphs, which concern connections among a collection of elements, are an example of a more complex entity which possesses several useful representations. For example, a simple directed graph of n elements (usually called nodes) may be represented by an n by n boolean matrix b (usually called an adjacency matrix) such that b[i;j]=1 if there is a connection from node i to node j . Each connection represented by a 1 in b is called an edge, and the graph can also be represented by a +/,b by n matrix in which each row shows the nodes connected by a particular edge.
Functions also admit different useful representations. For example, a permutation function, which yields a reordering of the elements of its vector argument x , may be represented by a permutation vector p such that the permutation function is simply x[p] , by a cycle representation which presents the structure of the function more directly. by the boolean matrix b←p∘.=⍳⍴p such that the permutation function is b+.×x , or by a radix representation r which employs one of the columns of the matrix 1+(⌽⍳n)⊤¯1+!n←⍴x , and has the property that 2|+/r-1 is the parity of the permutation represented.
In order to use different representations conveniently, it is important to be able to express the transformations between representations clearly and precisely. Conventional mathematical notation is often deficient in this respect, and the present section is devoted to developing expressions for the transformations between representations useful in a variety of topics: number systems, polynomials, permutations, graphs, and boolean algebra.
3.1 Number Systems
We will begin the discussion of representations with a familiar example, the use of different representations of positive integers and the transformations between them. Instead of the positional or base-value representations commonly treated, we will use prime decomposition, a representation whose interesting properties make it useful in introducing the idea of logarithms as well as that of number representation [6, Ch.16].
If p is a vector of the first ⍴p primes and e is a vector of non-negative integers, then e can be used to represent the number p×.*e , and all of the integers ⍳⌈/p can be so represented. For example, 2 3 5 7 ×.* 0 0 0 0 is 1 and 2 3 5 7 ×.* 1 1 0 0 is 6 and:
p
2 3 5 7
me
0 1 0 2 0 1 0 3 0 1
0 0 1 0 0 1 0 0 2 0
0 0 0 0 1 0 0 0 0 1
0 0 0 0 0 0 1 0 0 0
p×.*me
1 2 3 4 5 6 7 8 9 10
The similarity to logarithms can be seen in the identity:
×/p×.*me ←→ p×.*+/me
which may be used to effect multiplication by addition.
Moreover, if we define gcd and lcm to give the greatest common divisor and least common multiple of elements of vector arguments, then:
gcd p×.*me ←→ p×.*⌊/me
lcm p×.*me ←→ p×.*⌈/me
me v←p×.*me
2 1 0 v
3 1 2 18900 7350 3087
2 2 0 gcd v lcm v
1 3 4 21 926100
p×.*⌊/me p×.*⌈/me
21 926100
In defining the function gcd , we will use the operator / with a boolean argument b (as in b/). It produces the compression function which selects elements from its right argument according to the ones in b . For example, 1 0 1 0 1/⍳5 is 1 3 5 . Moreover, the function b/ applied to a matrix argument compresses rows (thus selecting certain columns), and the function b⌿ compresses columns to select rows. Thus:
gcd:gcd m,(m←⌊/r)|r:1≥⍴r←(⍵≠0)/⍵:+/r
lcm:(×/x)÷gcd x←(1↑⍵),lcm 1↓⍵:0=⍴⍵:1
The transformation to the value of a number from its prime decomposition representation (vfr) and the inverse transformation to the representation from the value (rpv) are given by:
vfr:⍺×.*⍵
rfv:d+⍺ rfv ⍵÷⍺×.*d:^/~d←0=⍺|⍵:d
For example:
p vfr 2 1 3 1
10500
p rfv 10500
2 1 3 1
3.2 Polynomials
Section 2 introduced two representations of a polynomial on a scalar argument x , the first in terms of a vector of coefficients c (that is, +/c×x*¯1+⍳⍴c), and the second in terms of its roots r (that is, ×/x-r). The coefficient representation is convenient for adding polynomials (c+d) and for obtaining derivatives (1↓cׯ1+⍳⍴c). The root representation is convenient for other purposes, including multiplication which is given by ri,r2 .
We will now develop a function cfr (Coefficients from Roots) which transforms a roots representation to an equivalent coefficient representation, and an inverse function rfc . The development will be informal; a formal derivation of cfr appears in Section 4.
The expression for cfr will be based on Newton’s symmetric functions, which yield the coefficients as sums over certain of the products over all subsets of the arithmetic negation (that is, -r) of the roots r . For example, the coefficient of the constant term is given by ×/-r , the product over the entire set, and the coefficient of the next term is a sum of the products over the elements of -r taken (⍴r)-1 at a time.
The function defined by A.2 can be used to give the products over all subsets as follows:
p←(-r)×.*m←T ⍴r
The elements of p summed to produce a given coefficient depend upon the number of elements of r excluded from the particular product, that is, upon +⌿~m , the sum of the columns of the complement of the boolean “subset” matrix T⍴r .
The summation over p may therefore be expressed as ((0,⍳⍴r)∘.=+⌿~m)+.×p , and the complete expression for the coefficients c becomes:
c←((0,⍳⍴r)∘.=+⌿~m)+.×(-r)×.*m←T ⍴r
For example, if r←2 3 5 , then
m +⌿~m
0 0 0 0 1 1 1 1 3 2 2 1 2 1 1 0
0 0 1 1 0 0 1 1 (0,⍳⍴r)∘.=+⌿~m
0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 1
(-r)×.*m 0 0 0 1 0 1 1 0
1 ¯5 ¯3 15 ¯2 10 6 ¯30 0 1 1 0 1 0 0 0
1 0 0 0 0 0 0 0
((0,⍳⍴r)∘.=+⌿~m)+.×(-r)×.*m←T ⍴r
¯30 31 ¯10 1
The function cfr which produces the coefficients from the roots may therefore be defined and used as follows:
| cfr:((0,⍳⍴⍵)∘.=+⌿~m)+.×(-⍵)×.*m←T ⍴⍵ | C.1 |
cfr 2 3 5
¯30 31 ¯10 1
(cfr 2 3 5) P x←1 2 3 4 5 6 7 8
¯8 0 0 ¯2 0 12 40 90
×/x∘.-2 3 5
¯8 0 0 ¯2 0 12 40 90
The inverse transformation rfc is more difficult, but can be expressed as a successive approximation scheme as follows:
rfc:(¯1+⍳⍴1↓⍵)g ⍵
g:(⍺-z)g ⍵:tol≥⌈/|z←⍺ step ⍵:⍺-z
step:(⌹(⍺∘.-⍺)×.*i∘.≠i←⍳⍴⍺)+.×(⍺∘.*¯1+⍳⍴⍵)+.×⍵
⎕←c←cfr 2 3 5 7
210 ¯247 101 ¯17 1
tol←1e¯8
rfc c
7 5 2 3
The order of the roots in the result is, of course, immaterial. The final element of any argument of rfc must be 1 , since any polynomial equivalent to ×/x-r must necessarily have a coefficient of 1 for the high order term.
The foregoing definition of rfc applies only to coefficients of polynomials whose roots are all real. The left argument of g in rfc provides (usually satisfactory) initial approximations to the roots, but in the general case some at least must be complex. The following example, using the roots of unity as the initial approximation, was executed on an APL system which handles complex numbers:
| (*○0j2×(¯1+⍳n)÷n←⍴1↓⍵)g ⍵ | C.2 |
⎕←c←cfr 1j1 1j¯1 1j2 1j¯2
10 ¯14 11 ¯4 1
rfc c
1j¯1 1j2 1j1 1j¯2
The monadic function ○ used above multiplies its argument by pi.
In Newton’s method for the root of a scalar function f , the next approximation is given by a←a-(f a)÷df a , where df is the derivative of f . The function step is the generalization of Newton’s method to the case where f is a vector function of a vector. It is of the form (⌹m)+.×b , where b is the value of the polynomial with coefficients ⍵ , the original argument of rfc , evaluated at ⍺ , the current approximation to the roots; analysis similar to that used to derive B.3 shows that m is the matrix of derivatives of a polynomial with roots ⍺ , the derivatives being evaluated at ⍺ .
Examination of the expression for m shows that its off-diagonal elements are all zero, and the expression (⌹m)+.×b may therefore be replaced by b÷d , where d is the vector of diagonal elements of m . Since (i,j)↓n drops i rows and j columns from a matrix n , the vector d may be expressed as ×/0 1↓(¯1+⍳⍴⍺)⌽⍺∘.-⍺ ; the definition of the function step may therefore be replaced by the more efficient definition:
| step:((⍺∘.*¯1+⍳⍴⍵)+.×⍵)÷×/0 1↓(¯1+⍳⍴⍺)⌽⍺∘.-⍺ | C.3 |
This last is the elegant method of Kerner [7]. Using starting values given by the left argument of g in C.2, it converges in seven steps (with a tolerance tol←1e¯8) for the sixth-order example given by Kerner.
3.3 Permutations
A vector p whose elements are some permutation of its indices (that is, ^/1=+/p∘.=⍳⍴p) will be called a permutation vector. If c is a permutation vector such that (⍴x)=⍴d , then x[d] is a permutation of x , and d will be said to be the direct representation of this permutation.
The permutation x[d] may also be expressed as b+.×x , where b is the boolean matrix d∘.=⍳⍴d . The matrix b will be called the boolean representation of the permutation. The transformations between direct and boolean representations are:
bfd:⍵∘.=⍳⍴⍵ dfb:⍵+.×⍳1↑⍴⍵
Because permutation is associative, the composition of permutations satisfies the following relations:
(x[d1])[d2] ←→ x[(d1 [d2])]
b2+.×(b1+.×x) ←→ (b2+.×b1)+.×x
The inverse of a boolean representation b is ⍋b , and the inverse of a direct representation is either ⍋d or d⍳⍳⍴d . (The grade function ⍋ grades its argument, giving a vector of indices to its elements in ascending order, maintaining existing order among equal elements. Thus ⍋3 7 1 4 is 3 1 4 2 and ⍋3 7 3 4 is 1 3 4 2 . The index-of function ⍳ determines the smallest index in its left argument of each element of its right argument. For example, 'abcde'⍳'babe' is 2 1 2 5 , and 'babe'⍳'abcde' is 2 1 5 5 4 .)
The cycle representation also employs
a permutation vector.
Consider a permutation vector c
and the segments of c marked off
by the vector c=⌊\c .
For example, if
7 3 6 5 2 1 4
Each block determines a “cycle” in the associated permutation in the sense that if r is the result of permuting x , then:
| r[7] is x[7] | ||
| r[3] is x[6] | r[6] is x[5] | r[5] is x[3] |
| r[2] is x[2] | ||
| r[1] is x[4] | r[4] is x[1] |
If the leading element of c is the smallest (that is, 1), then c consists of a single cycle, and the permutation of a vector x which it represents is given by x[c]←x[1⌽c] . For example:
x←'ABCDEFG'
c←1 7 6 5 2 4 3
x[c]←x[1⌽c]
gdacbef
Since x[q]←a is equivalent to x←a[⍋q] , it follows that x[c]←x[1⌽c] is equivalent to x←x[(1⌽c)[⍋c]] , and the direct representation vector d equivalent to c is therefore given (for the special case of a single cycle) by d←(1⌽c)[⍋c] .
In the more general case, the rotation of the complete vector (that is, 1⌽c) must be replaced by rotations of the individual subcycles marked off by c=⌊\c , as shown in the following definition of the transformation to direct from cycle representation:
dfc:(⍵[⍋x++\x←⍵=⌊\⍵])[⍋⍵]
If one wishes to catenate a collection of disjoint cycles to form a single vector c such that c=⌊\c marks off the individual cycles, then each cycle ci must first be brought to standard form by the rotation (¯1+ci⍳⌊/ci)⌽ci , and the resulting vectors must be catenated in descending order on their leading elements.
The inverse transformation from direct to cycle representation is more complex, but can be approached by first producing the matrix of all powers of d up to the ⍴dth, that is, the matrix whose successive columns are d and d[d] and (d[d])[d] , etc. This is obtained by applying the function pow to the one-column matrix d∘.+,0 formed from d , where pow is defined and used as follows:
pow←pow d,(d←⍵[;1])[⍵]:≤/⍴⍵:⍵
⎕←d←dfc c←7,3 6 5,2,1 4
4 2 6 1 3 5 7
pow d∘.+,0
4 1 4 1 4 1 4
2 2 2 2 2 2 2
6 5 3 6 5 3 6
1 4 1 4 1 4 1
3 6 5 3 6 5 3
5 3 6 5 3 6 5
7 7 7 7 7 7 7
If m←pow d∘.+,0 , then the cycle representation of d may be obtained by selecting from m only “standard” rows which begin with their smallest elements (ssr), by arranging these remaining rows in descending order on their leading elements (dol), and then catenating the cycles in these rows (cir). Thus:
cfd:cir dol ssr pow ⍵∘.+,0
ssr:(∧/m=1⌽m←⌊\⍵)⌿⍵
dol:⍵[⍒⍵[;1];]
cir:(,1,∧\0 1↓⍵≠⌊\⍵)/,⍵
dfc c←7,3 6 5,2,1 4
4 2 6 1 3 5 7
cfd dfc c
7 3 6 5 2 1 4
In the definition of dol , indexing is applied to matrices. The indices for successive coordinates are separated by semicolons, and a blank entry for any axis indicates that all elements along it are selected. Thus m[;1] selects column 1 of m .
The cycle representation is convenient for determining the number of cycles in the permutation represented (nc:+/⍵=⌊\⍵), the cycle lengths (cl:x-0,¯1↓x←(1⌽⍵=⌊\⍵)/⍳⍴⍵), and the power of the permutation (pp:lcm cl ⍵). On the other hand, it is awkward for composition and inversion.
The !n column vectors of the matrix (⌽⍳n)⊤¯1+⍳!n are all distinct, and therefore provide a potential radix representation [8] for the !n permutations of order n . We will use instead a related form obtained by increasing each element by 1 :
rr:1+(⌽⍳⍵)⊤¯1+⍳!⍵
rr 4
1 1 1 1 1 1 2 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 4 4
1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3
1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Transformations between this representation and the direct form are given by:
dfr:⍵[1],x+⍵[1]≤x←dfr 1↓⍵:0=⍴⍵:⍵
rfd:⍵[1],rfd x-⍵[1]≤x←1↓⍵:0=⍴⍵:⍵
Some of the characteristics of this alternate representation are perhaps best displayed by modifying dfr to apply to all columns of a matrix argument, and applying the modified function mf to the result of the function rr .
mf:⍵[,1;],[1]x+⍵[(1 ⍴x)⍴1;]≤x←mf 1 0↓⍵:0=1↑⍴⍵:⍵
mf rr 4
1 1 1 1 1 1 2 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 4 4
2 2 3 3 4 4 1 1 3 3 4 4 1 1 2 2 4 4 1 1 2 2 3 3
3 4 2 4 2 3 3 4 1 4 1 3 2 4 1 4 1 2 2 3 1 3 1 2
4 3 4 2 3 2 4 3 4 1 3 1 4 2 4 1 2 1 3 2 3 1 2 1
The direct permutations in the columns of this result occur in lexical order (that is, in ascending order on the first element in which two vectors differ); this is true in general, and the alternate representation therefore provides a convenient way for producing direct representations in lexical order.
The alternate representation also has the useful property that the parity of the direct permutation d is given by 2|+/¯1+rfd d , where m|n represents the residue of n modulo m . The parity of a direct representation can also be determined by the function:
par:2|+/,(i∘.>i←⍳⍴⍵)∧⍵∘.>⍵
3.4 Directed Graphs
A simple directed graph is defined by a set of k nodes and a set of directed connections from one to another of pairs of the nodes. The directed connections may be conveniently represented by a k by k boolean connection matrix c in which c[i;j]=1 denotes a connection from the ith node to the jth.
For example, if the four nodes of a graph are represented by n←'qrst' , and if there are connections from node s to node q , from r to t , and from t to q , then the corresponding connection matrix is given by:
0 0 0 0
0 0 0 1
1 0 0 0
1 0 0 0
A connection from a node to itself (called a self-loop) is not permitted, and the diagonal of a connection matrix must therefore be zero.
If p is any permutation vector of order ⍴n , then n1←n[p] is a reordering of the nodes, and the corresponding connection matrix is given by c[p;p] . We may (and will) without loss of generality use the numeric labels ⍳⍴n it for the nodes, because if n is any arbitrary vector of names for the nodes and l is any list of numeric labels, then the expression q←n[l] gives the corresponding list of names and, conversely, n⍳q gives the list l of numeric labels.
The connection matrix c is convenient for expressing many useful functions on a graph. For example, +/c gives the out-degrees of the nodes, +⌿c gives the in-degrees, +/,c gives the number of connections or edges, ⍉c gives a related graph with the directions of edges reversed, and c∨⍉c gives a related “symmetric” or “undirected” graph. Moreover, if we use the boolean vector b←∨/(⍳1⍴c)∘.=l to represent the list of nodes l , then b∨.∧c gives the boolean vector which represents the set of nodes directly reachable from the set b . Consequently, c∨.∧c gives the connections for paths of length two in the graph c , and c∨c∨.∧c gives connections for paths of length one or two. This leads to the following function for the transitive closure of a graph, which gives all connections through paths of any length:
tc:tc z:∧/,⍵=z←⍵∨⍵∨.∧⍵:z
Node j is said to be reachable from node i if (tc c)[i;j]=1 . A graph is strongly-connected if every node is reachable from every node, that is ^/,tc c .
If d←tc c and d[i;j]=1 for some i , then node i is reachable from itself through a path of some length; the path is called a circuit, and node i is said to be contained in a circuit.
A graph t is called a tree if it has no circuits and its in-degrees do not exceed 1 , that is, ∧/1≥+⌿t . Any node of a tree with an in-degree of 0 is called a root, and if k←+/0=+⌿t , then t is called a k-rooted tree. Since a tree is circuit-free, k must be at least 1 . Unless otherwise stated, it is normally assumed that a tree is singly-rooted (that is, k=1); multiply-rooted trees are sometimes called forests.
A graph c covers a graph d if ^/,c≥d . If g is a strongly-connected graph and t is a (singly-rooted) tree, then t is said to be a spanning tree of g if c covers t and if all nodes are reachable from the root of t , that is,
(∧/,g≥t) ∧ ∧/r∨r∨.∧tc t
where r is the (boolean representation of the) root of t .
A depth-first spanning tree [9] of a graph g is a spanning tree produced by proceeding from the root through immediate descendants in g , always choosing as the next node a descendant of the latest in the list of nodes visited which still possesses a descendant not in the list. This is a relatively complex process which can be used to illustrate the utility of the connection matrix representation:
| dfst:((,1)∘.=k)r ⍵∧k∘.∨~k←⍺=⍳1↑⍴⍵ | C.4 |
r:(c,[1]⍺)r ⍵∧p∘.∨~c←<\u∧p∨.∧⍵
:~∨/p←(<\⍺∨.∧⍵∨.∧u←~∨⌿⍺)∨.∧⍺
:⍵
Using as an example the graph g from [9]:
g 1 dfst g
0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0
0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0
0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1
1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
The function dfst establishes the left argument of the recursion r as the one-row matrix representing the root specified by the left argument of dfst , and the right argument as the original graph with the connections into the root k deleted. The first line of the recursion r shows that it continues by appending on the top of the list of nodes thus far assembled in the left argument the next child c , and by deleting from the right argument all connections into the chosen child c except the one from its parent p . The child c is chosen from among those reachable from the chosen parent (p∨.∧⍵). but is limited to those as yet untouched (u^p∨.∧⍵), and is taken, arbitrarily, as the first of these (<\u^p∨.∧⍵).
The determinations of p and u are shown in the second line, p being chosen from among those nodes which have children among the untouched nodes (⍵∨.∧u). These are permuted to the order of the nodes in the left argument (⍺∨.∧⍵∨.∧u), bringing them into an order so that the last visited appears first, and p is finally chosen as the first of these.
The last line of r shows the final result to be the resulting right argument ⍵ , that is, the original graph with all connections into each node broken except for its parent in the spanning tree. Since the final value of ⍺ is a square matrix giving the nodes of the tree in reverse order as visited, substitution of ⍵,⌽[1]⍺ (or, equivalently, ⍵,⊖⍺) for ⍵ would yield a result of shape 1 2×⍴g containing the spanning tree followed by its “preordering” information.
Another representation of directed graphs often used, at least implicitly, is the list of all node pairs v,w such that there is a connection from v to w . The transformation to this list form from the connection matrix may be defined and used as follows:
lfc←(,⍵)/1+d⊤¯1+⍳×/d←⍴⍵
c lfc c
0 0 1 1 1 1 2 3 3 4
0 0 1 0 3 4 3 2 4 1
0 1 0 1
1 0 0 0
However, this representation is deficient since it does not alone determine the number of nodes in the graph, although in the present example this is given by ⌈/,lfc c because the highest numbered node happens to have a connection. A related boolean representation is provided by the expression (lfc c)∘.=⍳1↑⍴c , the first plane showing the out- and the second showing the in-connections.
An incidence matrix representation often used in the treatment of electric circuits [10] is given by the difference of these planes as follows:
ifc:-⌿(lfc ⍵)∘.=⍳1↑⍴⍵
For example:
(lfc c)∘.=⍳1↑⍴c ifc c
1 0 0 0 1 0 ¯1 0
1 0 0 0 1 0 0 ¯1
0 1 0 0 0 1 ¯1 0
0 0 1 0 0 ¯1 1 0
0 0 1 0 0 0 1 ¯1
0 0 0 1 ¯1 0 0 1
0 0 1 0
0 0 0 1
0 0 1 0
0 1 0 0
0 0 0 1
1 0 0 0
In dealing with non-directed graphs, one sometimes uses a representation derived as the or over these planes (∨⌿). This is equivalent to |ifc c .
The incidence matrix i has a number of useful properties. For example, +/i is zero, +⌿i gives the difference between the in- and out-degrees of each node, ⍴i gives the number of edges followed by the number of nodes, and ×/⍴i gives their product. However, all of these are also easily expressed in terms of the connection matrix, and more significant properties of the incidence matrix are seen in its use in electric circuits. For example, if the edges represent components connected between the nodes, and if v is the vector of node voltages, then the branch voltages are given by i+.×v ; if bi is the vector of branch currents, the vector of node currents is given by bi+.×i .
The inverse transformation from incidence matrix to connection matrix is given by:
cfi:d⍴(¯1+⍳×/d)∊d⊥(1 ¯1∘.=⍵)+.ׯ1+⍳1↓d←⌊\⌽⍴⍵
The set membership function ∊ yields a boolean array, of the same shape as its left argument, which shows which of its elements belong to the right argument.
3.5 Symbolic Logic
A boolean function of n arguments may be represented by a boolean vector of 2*n elements in a variety of ways, including what are sometimes called the disjunctive, conjunctive, equivalence, and exclusive-disjunctive forms. The transformation between any pair of these forms may be represented concisely as some 2*n by 2*n matrix formed by a related inner product, such as t∨.∧⍉t , where t←T n is the “truth table” formed by the function T defined by A.2. These matters are treated fully in [11, Ch.7].4. Identities and Proofs
In this section we will introduce some widely used identities and provide formal proofs for some of them, including Newton’s symmetric functions and the associativity of inner product, which are seldom proved formally.4.1 Dualities in Inner Products
The dualities developed for reduction and scan extend to inner products in an obvious way. If df is the dual of f and dg is the dual of g with respect to a monadic function m with inverse mi , and if a and b are matrices, then:
a f.g b ←→ mi (m a) df.dg (m b)
For example:
a∨.∧b ←→ ~(~a)∧.∨(~b)
a^.=b ←→ ~(~a)∨.≠(~b)
a⌊.+b ←→ -(-a)⌈.+(-b)
The dualities for inner product, reduction, and scan can be used to eliminate many uses of boolean negation from expressions, particularly when used in conjunction with identities of the following form:
a^(~b) ←→ a>b
(~a)^b ←→ a<b
(~a)^(~b) ←→ a⍱b
4.2 Partitioning Identities
Partitioning of an array leads to a number of obvious and useful identities. For example:
×/3 1 4 2 6 ←→ (×/3 1) × (×/4 2 6)
More generally, for any associative function f :
f/v ←→ (f/k↑v) f (f/k↓v)
f/v,w ←→ (f/v) f (f/w)
If f is commutative as well as associative, the partitioning need not be limited to prefixes and suffixes, and the partitioning can be made by compression by a boolean vector u :
f/v ←→ (f/u/v) f (f/(~u)/v)
If e is an empty vector (0=⍴e), the reduction f/e yields the identity element of the function f , and the identities therefore hold in the limiting cases 0=k and 0=∨/u .
Partitioning identities extend to matrices in an obvious way. For example, if v , m , and a are arrays of ranks 1 , 2 , and 3 , respectively, then:
| v+.×m ←→ ((k↑v)+.×(k,1↓⍴m)↑m)+(k↓v)+.×(k,0)↓m | D.1 |
| (i,j)↓a+.×v ←→ ((i,j,0)↓a)+.×v | D.2 |
4.3 Summarization and Distribution
Consider the definition and and use of the following functions:
| N:(∨⌿<\⍵∘.=⍵)/⍵ | D.3 |
| S:(N⍵)∘.=⍵ | D.4 |
a←3 3 1 4 1
c←10 20 30 40 50
N a S a (S a)+.×c
3 1 4 1 1 0 0 0 30 80 40
0 0 1 0 1
0 0 0 1 0
The function a selects from a vector argument its nub, that is, the set of distinct elements it contains. The expression S a gives a boolean “summarization matrix” which relates the elements of a to the elements of its nub. If a is a vector of account numbers and c is an associated vector of costs, then the expression (S a)+.×c evaluated above sums or “summarizes” the charges to the several account numbers occurring in a .
Used as postmultiplier, in expressions of the form w+.×S a , the summarization matrix can be used to distribute results. For example, if f is a function which is costly to evaluate and its argument v has repeated elements, it may be more efficient to apply f only to the nub of v and distribute the results in the manner suggested by the following identity:
| f v ←→ (f N v)+.×S v | D.5 |
The order of the elements of S v is the same as their order in v , and it is sometimes more convenient to use an ordered nub and corresponding ordered summarization given by:
| ON:N⍵[⍋⍵] | D.6 |
| OS:(ON⍵)∘.=⍵ | D.7 |
The identity corresponding to D.5 is:
| f v ←→ (f ON v)+.×OS v | D.8 |
The summarization function produces an interesting result when applied to the function T defined by A.2:
(+/S+⌿T n) ←→ (0,⍳n)!n
In words, the sums of the rows of the summarization matrix of the column sums of the subset matrix of order n is the vector of binomial coefficients of order n .
4.4 Distributivity
The distributivity of one function over another is an important notion in mathematics, and we will now raise the question of representing this in a general way. Since multiplication distributes to the right over addition we have a×(b+q)←→ab+aq , and since it distributes to the left we have (a+p)×b←→ab+pb . These lead to the more general cases:
(a+p)×(b+q) ←→ ab+aq+pb+pq(a+p)×(b+q)×(c+r) ←→ abc+abr+aqc+aqr+pbc+pbr+pqc+pqr
(a+p)×(b+q)× ... ×(c+r) ←→ ab...c+ .... +pq...r
Using the notion that v←a,b and u←p,q or v←a,b,c and w←p,q,r , etc., the left side can be written simply in terms of reduction as ×/v+w . For this case of three elements, the right side can be written as the sum of the products over the columns of the following matrix:
v[0] v[0] v[0] v[0] w[0] w[0] w[0] w[0]
v[1] v[1] w[1] w[1] v[1] v[1] w[1] w[1]
v[2] w[2] v[2] w[2] v[2] w[2] v[2] w[2]
The pattern of v’s and w’s above is precisely the pattern of zeros and ones in the matrix t←T⍴v , and so the products down the columns are given by (v×.*~t)×(w×.*t) . Consequently:
| ×/v+w ←→ +/(v×.*~t)×w×.*t←T ⍴v | D.9 |
We will now present a formal inductive proof of D.9, assuming as the induction hypothesis that D.9 is true for all v and w of shape n (that is, ^/n=(⍴v),⍴w) and proving that it holds for shape n+1 , that is, for x,v and y,w , where x and y are arbitrary scalars.
For use in the inductive proof we will first give a recursive definition of the function T , equivalent to A.2 and based on the following notion: if m+T 2 is the result of order 2 , then:
m
0 0 1 1
0 1 0 1
0,[1]m 1,[1]m
0 0 0 0 1 1 1 1
0 0 1 1 0 0 1 1
0 1 0 1 0 1 0 1
(0,[1]m),(1,[1]m)
0 0 0 0 1 1 1 1
0 0 1 1 0 0 1 1
0 1 0 1 0 1 0 1
Thus:
| T:(0,[1]T),(1,[1]t←T⍵-1):0=⍵:0 1⍴0 | D.10 |
| +/((c←x,v)×.*~q)×d×.*q←T⍴(d←y,w) | |
| +/(c×.*~z,u)×d×.*(z←0,[1] t),u←1,[1] t←T⍴w | D.10 |
| +/((c×.*~z),c×.*~u)×(d×.*z),d×.*u | Note 1 |
| +/((c×.*~z),c×.*~u)×((y*0)×w×.*t),(y*1)×w×.*t | Note 2 |
| +/((c×.*~z),c×.*~u)×(w×.*t),y×w×.*t | y*0 1←→1,y |
| +/((x×v×.*~t),v×.*~t)×(w×.*t),y×w×.*t | Note 2 |
| +/(x×(v×.*~t)×w×.*t),(y×(v×.*~t)×w×.*t) | Note 3 |
| +/(x××/v+w),(y××/v+w) | Induction hypothesis |
| +/(x,y)××/v+w (x×s),(y×s)←→(x,y)×s | |
| ×/(x+y),(v+w) | Definition of ×/ |
| ×/(x,v)+(y,w) | + distributes over , |
Note 1: m+.×n,p ←→ (m+.×n),m+.×p (partitioning identity on matrices)
Note 2: v+.×m ←→ ((1↑v)+.×(1,1↓⍴m)↑m)+(1↓v)+.×1 0↓m (partitioning identity on matrices and the definition of c , d , z , and u )
Note 3: (v,w)×p,q ←→ (v×p),w×q
To complete the inductive proof we must show that the putative identity D.9 holds for some value of n . If n=0 , the vectors a and b are empty, and therefore x,a ←→ ,x and y,b ←→ ,y . Hence the left side becomes ×/x+y , or simply x+y . The right side becomes +/(x×.*~q)×y×.*q , where ~q is the one-rowed matrix 1 0 and q is 0 1 . The right side is therefore equivalent to +/(x,1)×(1,y) , or x+y . Similar examination of the case n=1 may be found instructive.
4.5 Newton’s Symmetric Functions
If x is a scalar and r is any vector, then ×/x-r is a polynomial in x having the roots r . It is therefore equivalent to some polynomial c P x , and assumption of this equivalence implies that c is a function of r . We will now use D.8 and D.9 to derive this function, which is commonly based on Newton’s symmetric functions:
| ×/x-r | |
| ×/x+(-r) | |
| +/(x×.*~t)×(-r)×.*t←T ⍴r | D.9 |
| (x×.*~t)+.×p←(-r)×.*t | Def of +.× |
| (x*s←+⌿~t)+.×p | Note 1 |
| ((x*ON s)+.×OS s)+.×p | D.8 |
| (x*ON s)+.×((OS s)+.×p) | +.× is associative |
| (x*0,⍳⍴r)+.×((OS s)+.×p) | Note 2 |
| ((OS s)+.×p)P x | B.1 (polynomial) |
| ((OS +⌿~t)+.×((-r)×.*t←T ⍴r))P x | Defs of s and p |
Note 1: If x is a scalar and b is a boolean vector, then x×.*b ←→ x*+/b .
Note 2: Since t is boolean and has ⍴r rows, the sums of its columns range from 0 to ⍴r , and their ordered nub is therefore 0,⍳⍴r .
4.6 Dyadic Transpose
The dyadic transpose, denoted by ⍉ , is a generalization of monadic transpose which permutes axes of the right argument, and (or) forms “sectors” of the right argument by coalescing certain axes, all as determined by the left argument. We introduce it here as a convenient tool for treating properties of the inner product.
The dyadic transpose will be defined formally in terms of the selection function
sf:(,⍵)[1+(⍴⍵)⊥⍺-1]
which selects from its right argument the element whose indices are given by its vector left argument, the shape of which must clearly equal the rank of the right argument. The rank of the result of k⍉a is ⌈/k , and if i is any suitable left argument of the selection i sf k⍉a then:
| i sf k⍉a ←→ (i[k])sf a | D.11 |
For example, if m is a matrix, then 2 1 ⍉m ←→ ⍉m and 1 1 ⍉m is the diagonal of m ; if t is a rank three array, then 1 2 2 ⍉m is a matrix “diagonal section” of t produced by running together the last two axes, and the vector 1 1 1 ⍉t is the principal body diagonal of t .
The following identity will be used in the sequel:
| j⍉k⍉a ←→ (j[k])⍉a | D.12 |
Proof:
| i sf j⍉k⍉a | |
| (i[j]) sf k⍉a | Definition of ⍉ (D.11) |
| ((i[j])[k]) sf a | Definition of ⍉ |
| (i[(j[k])]) sf a | Indexing is associative |
| i sf(j[k])⍉a | Definition of ⍉ |
4.7 Inner Products
The following proofs are stated only for matrix arguments and for the particular inner product +.× . They are easily extended to arrays of higher rank and to other inner products f.g , where f and g need possess only the properties assumed in the proofs for + and × .
The following identity (familiar in mathematics as a sum over the matrices formed by (outer) products of columns of the first argument with corresponding rows of the second argument) will be used in establishing the associativity and distributivity of the inner product:
| m+.×n ←→ +/1 3 3 2 ⍉ m∘.×n | D.13 |
Proof: (i,j)sf m+.×n is defined as the sum over v , where v[k] ←→ m[i;k]×n[k;j] . Similarly,
(i,j)sf +/1 3 3 2 ⍉ m∘.×n
is the sum over the vector w such that
w[k] ←→ (i,j,k)sf 1 3 3 2 ⍉ m∘.×n
Thus:
| w[k] | |
| (i,j,k)sf 1 3 3 2 ⍉ m∘.×n | |
| (i,j,k)[1 3 3 2]sf m∘.×n | D.12 |
| (i,k,k,j)sf m∘.×n | Def of indexing |
| m[i;k]×n[k;j] | Def of Outer product |
| v[k] |
Matrix product distributes over addition as follows:
| m+.×(n+p) ←→ (m+.×n)+(m+.×p) | D.14 |
Proof:
| m+.×(n+p) | |
| +/(j← 1 3 3 2)⍉m∘.×(n+p) | D.13 |
| +/j⍉(m∘.×n)+(m∘.×p) | × distributes over + |
| +/(j⍉m∘.×n)+(j⍉m∘.×p) | ⍉ distributes over + |
| (+/j⍉m∘.×n)+(+/j⍉m∘.×p) | + is assoc and comm |
| (m+.×n)+(m+.×p) | D.13 |
Matrix product is associative as follows:
| m+.×(n+p) ←→ (m+.×n)+.×p | D.15 |
Proof: We first reduce each of the sides to sums over sections of an outer product, and then compare the sums. Annotation of the second reduction is left to the reader:
| m+.×(n+.×p) | |
| m+.×+/1 3 3 2⍉n∘.×p | D.12 |
| +/1 3 3 2⍉m∘.×+/1 3 3 2⍉n∘.×p | D.12 |
| +/1 3 3 2⍉+/m∘.×1 3 3 2⍉n∘.×p | × distributes over + |
| +/1 3 3 2⍉+/1 2 3 5 5 4⍉m∘.×n∘.×p | Note 1 |
| +/+/1 3 3 2 4 ⍉1 2 3 5 5 4⍉m∘.×n∘.×p | Note 2 |
| +/+/1 3 3 4 4 2⍉m∘.×n∘.×p | D.12 |
| +/+/1 3 3 4 4 2⍉(m∘.×n)∘.×p | × is associative |
| +/+/1 4 4 3 3 2⍉(m∘.×n)∘.×p | + is associative and commutative |
| (m+.×n)+.×p | |
| (+/1 3 3 2⍉m∘.×n)+.×p | |
| +/1 3 3 2⍉(+/1 3 3 2⍉m∘.×n)∘.×p | |
| +/1 3 3 2⍉+/1 5 5 2 3 4⍉(m∘.×n)∘.×p | |
| +/+/1 3 3 2 4⍉1 5 5 2 3 4⍉(m∘.×n)∘.×p | |
| +/+/1 4 4 3 3 2⍉(m∘.×n)∘.×p |
Note 1: +/m∘.×j⍉a ←→ +/((⍳⍴⍴m),j+⍴⍴m)⍉m∘.×a
Note 2: j⍉+/a ←→ +/(j,1+⌈/j)⍉a
4.8 Product of Polynomials
The identity B.2 used for the multiplication of polynomials will now be developed formally:
| (b P x)×(c P x) | |
| (+/b×x*e←¯1+⍳⍴b)×(+/c×x*f←¯1+⍳⍴c) | B.1 |
| +/+/(b×x*e)∘.×(+/c×x*f) | Note 1 |
| +/+/(b∘.×c)×((x*e)∘.×(x*f)) | Note 2 |
| +/+/(b∘.×c)×(x*(e∘.+f)) | Note 3 |
Note 1: (+/v)×(+/w)←→+/+/v∘.×x because × distributes over + and + is associative and commutative, or see [12, P21] for a proof.
Note 2: The equivalence of (p×v)∘.×(q×w) and (p∘.×q)×(v∘×w) can be established by examining a typical element of each expression.
Note 3: (x*i)×(x*j) ←→ x*(i+j)
The foregoing is the proof presented, in abbreviated form, by Orth [13, p.52], who also defines functions for the composition of polynomials.
4.9 Derivative of a Polynomial
Because of their ability to approximate a host of useful functions, and because they are closed under addition, multiplication, composition, differentiation, and integration, polynomial functions are very attractive for use in introducing the study of calculus. Their treatment in elementary calculus is, however, normally delayed because the derivative of a polynomial is approached indirectly, as indicated in Section 2, through a sequence of more general results.
The following presents a derivation of the derivative of a polynomial directly from the expression for the slope of the secant line through the points x,f x and (x+y),f(x+y) :
| ((c P x+y)-(c P x))÷y | |
| ((c P x+y)-(c P x+0))÷y | |
| ((c P x+y)-((0*j)+.×(a←ds j∘.!j←¯1+⍳⍴c)+.×c) P x)÷y B.6 | |
| ((((y*j)+.×m) P x)-((0*j)+.×m←a+.×c) P x)÷y B.6 | |
| ((((y*j)+.×m)-(0*j)+.×m) P x)÷y | P distributes over - |
| ((((y*j)-0*j)+.×m) P x)÷y | +.× distributes over - |
| (((0,y*1↓j)+.×m) P x)÷y | Note 1 |
| (((y*1↓j)+.× 1 0 ↓m) P x)÷y | D.1 |
| (((y*1↓j)+.×(1 0 0 ↓a)+.×c) P x)÷y | D.2 |
| ((y*1↓j-1)+.×(1 0 0 ↓a)+.×c) P x | (y*a)÷y←→y*a-1 |
| ((y*¯1+⍳¯1+⍴c)+.×(1 0 0 ↓a)+.×c) P x | Def of j |
| (((y*¯1+⍳¯1+⍴c)+.× 1 0 0 ↓a)+.×c) P x | D.15 |
Note 1: 0*0←→1←→y*0 and ^/0=0*1↓j
The derivative is the limiting value of the secant slope for y at zero, and the last expression above can be evaluated for this case because if e←¯1+⍳¯1+⍴c is the vector of exponents of y , then all elements of e are non-negative. Moreover, 0*e reduces to a 1 followed by zeros, and the inner product with 1 0 0↓a therefore reduces to the first plane of 1 0 0↓a or, equivalently, the second plane of a .
If b←j∘.!j←¯1+⍳⍴c is the matrix of binomial coefficients, then a is ds b and, from the definition of ds in B.5, the second plane of a is b×1=j∘.-j , that is, the matrix b with all but the first super-diagonal replaced by zeros. The final expression for the coefficients of the polynomial which is the derivative of the polynomial c P ⍵ is therefore:
((j∘.!j)×1=-j∘.-j←¯1+⍳⍴c)+.×c
For example:
c ← 5 7 11 13
(j∘.!j)×1=-j∘.-j←¯1+⍳⍴c
0 1 0 0
0 0 2 0
0 0 0 3
0 0 0 0
((j∘.!j)×1=-j∘.-j←¯1+⍳⍴c)+.×c
7 22 39 0
Since the superdiagonal of the binomial coefficient matrix (⍳n)∘.!⍳n is (¯1+⍳n-1)!⍳n-1 , or simply ⍳n-1 , the final result is 1⌽cׯ1+⍳⍴c in agreement with the earlier derivation.
In concluding the discussion of proofs, we will re-emphasize the fact that all of the statements in the foregoing proofs are executable, and that a computer can therefore be used to identify errors. For example, using the canonical function definition mode [4, p.81], one could define a function f whose statements are the first four statements of the preceding proof as follows:
∇f [1] ((c P x+y)-(c P x))÷y [2] ((c P x+y)-(c P x+0))÷y [3] ((c P x+y)-((0*j)+.×(a←ds j∘.!j←¯1+⍳⍴c)+.×c) P x)÷y [4] ((((y*j)+.×m) P x)-((0*j)+.×m←a+.×c) P x)÷y ∇
The statements of the proof may then be executed by assigning values to the variables and executing f as follows:
c←5 2 3 1
y←5
x←3 x←⍳10
f f
132 66 96 132 174 222 276 336 402 474 552
132 66 96 132 174 222 276 336 402 474 552
132 66 96 132 174 222 276 336 402 474 552
132 66 96 132 174 222 276 336 402 474 552
The annotations may also be added as comments between the lines without affecting the execution.
5. Conclusion
The preceding sections have attempted to develop the thesis that the properties of executability and universality associated with programming languages can be combined, in a single language, with the well-known properties of mathematical notation which make it such an effective tool of thought. This is an important question which should receive further attention, regardless of the success or failure of this attempt to develop it in terms of APL.
In particular, I would hope that others would treat the same question using other programming languages and conventional mathematical notation. If these treatments addressed a common set of topics, such as those addressed here, some objective comparisons of languages could be made. Treatments of some of the topics covered here are already available for comparison. For example, Kerner [7] expresses the algorithm C.3 in both ALGOL and conventional mathematical notation.
This concluding section is more general, concerning comparisons with mathematical notation, the problems of introducing notation, extensions to APL which would further enhance its utility, and discussion of the mode of presentation of the earlier sections.
5.1 Comparison with Conventional Mathematical Notation
Any deficiency remarked in mathematical notation can probably be countered by an example of its rectification in some particular branch of mathematics or in some particular publication; comparisons made here are meant to refer to the more general and commonplace use of mathematical notation.
APL is similar to conventional mathematical notation in many important respects: in the use of functions with explicit arguments and explicit results, in the concomitant use of composite expressions which apply functions to the results of other functions, in the provision of graphic symbols for the more commonly used functions, in the use of vectors, matrices, and higher-rank arrays, and in the use of operators which, like the derivative and the convolution operators of mathematics, apply to functions to produce functions.
In the treatment of functions APL differs in providing a precise formal mechanism for the definition of new function. The direct definition form used in this paper is perhaps most appropriate for purposes of exposition and analysis, but the canonical form referred to in the introduction, and defined in [4, p.81], is often more convenient for other purposes.
In the interpretation of composite expressions APL agrees in the use of parentheses, but differs in eschewing hierarchy so as to treat all functions (user-defined as well as primitive) alike, and in adopting a single rule for the application of both monadic and dyadic functions: the right argument of a function is the value of the entire expression to its right. An important consequence of this rule is that any portion of an expression which is free of parentheses may be read analytically from left to right (since the leading function at any stage is the “outer” or overall function to be applied to the result on its right), and constructively from right to left/since the rule is easily seen to be equivalent to the rule that execution is carried out from right to left).
Although Cajori does not even mention rules for the order of execution in his two-volume history of mathematical notations, it seems reasonable to assume that the motivation for the familiar hierarchy (power before × and × before + or -) arose from a desire to make polynomials expressible without parentheses. The convenient use of vectors in expressing polynomials, as in +/c×x*e , does much to remove this motivation. Moreover, the rule adopted in APL also makes Horner’s efficient expression for a polynomial expressible without parentheses:
+/3 4 2 5×x*0 1 2 3 ←→ 3+x×4+x×2+x×5
In providing graphic symbols for commonly used functions APL goes much farther, and provides symbols for functions (such as the power function) which are implicitly denied symbols in mathematics. This becomes important when operators are introduced; in the preceding sections the inner product ×.* (which must employ a symbol for power) played an equal role with the ordinary inner product +.x . Prohibition of elision of function symbols (such as ×) makes possible the unambigious use of multi-character names for variables and functions.
In the use of arrays APL is similar to mathematical notation, but more systematic. For example, v+w has the same meaning in both, and in APL the definitions for other functions are extended in the same element-by-element manner. In mathematics, however, expressions such as vxw and v*w are defined differently or not at all.
For example, v×w commonly denotes the vector product [14, p.308]. It can be expressed in various ways in APL. The definition
vp:((1⌽⍺)ׯ1⌽⍵)-(¯1⌽⍺)×1⌽⍵
provides a convenient basis for an obvious proof that vp is “anticommutative” (that is, v vp w ←→ -w vp v), and (using the fact that ¯1⌽x ←→ 2⌽x for 3-element vectors) for a simple proof that in 3-space v and w are both orthogonal to their vector product, that is, ∧/0=v+.×v vp w and ∧/0=w+.×v vp w .
APL is also more systematic in the use of operators to produce functions on arrays: reduction provides the equivalent of the sigma and pi notation (in +/ and */) and a host of similar useful cases; outer product extends the outer product of tensor anaysis to functions other than × , and inner product extends ordinary matrix product (+.×) to many cases, such as ∨.∧ and ⌊.+ , for which ad hoc definitions are often made.
Fig. 3.
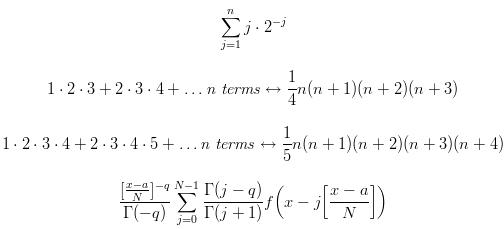
The similarities between APL and conventional notation become more apparent when one learns a few rather mechanical substitutions, and the translation of mathematical expressions is instructive. For example, in an expression such as the first shown in Figure 3, one simply substitutes ⍳n for each occurrence of j and replaces the sigma by +/ . Thus:
+/(⍳n)×2*-⍳n , or +/j×2*-j←⍳n
Collections such as Jolley’s Summation of Series [15] provide interesting expressions for such an exercise, particularly if a computer is available for execution of the results. For example, on pages 8 and 9 we have the identities shown in the second and third examples of Figure 3. These would be written as:
+/×/(¯1+⍳n)∘.+⍳3 ←→ (×/n+0,⍳3)÷4
+/×/(¯1+⍳n)∘.+⍳4 ←→ (×/n+0,⍳4)÷5
Together these suggest the following identity:
+/×/(¯1+⍳n)∘.+⍳k ←→ (×/n+0,⍳k)÷k+1
The reader might attempt to restate this general identity (or even the special case where k=0) in Jolley’s notation.
The last expression of Figure 3 is taken from a treatment of the fractional calculus [16, p.30], and represents an approximation to the qth order derivative of a function f. It would be written as:
(s*-q)×+/(j!j-1+q)×f x-(j←¯1+⍳n)×s←(x-a)÷n
The translation to APL is a simple use of ⍳n as suggested above, combined with a straightforward identity which collapses the several occurrences of the gamma function into a single use of the binomial coefficient function ! , whose domain is, of course, not restricted to integers.
In the foregoing, the parameter q specifies the order of the derivative if positive, and the order of the integral (from a to x) if negative. Fractional values give fractional derivatives and integrals, and the following function can, by first defining a function f and assigning suitable values to n and a , be used to experiment numerically with the derivatives discussed in [16]:
os:(s*-⍺)×+/(j!j-1+⍺)×f⍵-(j←¯1+⍳n)×s←(⍵-a)÷n
Although much use is made of “formal” manipulation in mathematical notation, truly formal manipulation by explicit algorithms is very difficult. APL is much more tractable in this respect. In Section 2 we saw, for example, that the derivative of the polynomial expression (⍵∘.*¯1+⍳⍴⍺)+.×⍺ is given by (⍵∘.*¯1+⍳⍴⍺)+.×1⌽⍺ׯ1+⍳⍴⍺ , and a set of functions for the formal differentiation of APL expressions given by Orth in his treatment of the calculus [13] occupies less than a page. Other examples of functions for formal manipulation occur in [17, p.347] in the modeling operators for the vector calculus.
Further discussion of the relationship with mathematical notation may be found in [3] and in the paper “Algebra as a Language” [6, p.325].
A final comment on printing, which has always been a serious problem in conventional notation. Although APL does employ certain symbols not yet generally available to publishers, it employs only 88 basic characters, plus some composite characters formed by superposition of pairs of basic characters. Moreover, it makes no demands such as the inferior and superior lines and smaller type fonts used in subscripts and superscripts.
5.2 The Introduction of Notation
At the outset, the ease of introducing notation in context was suggested as a measure of suitability of the notation, and the reader was asked to observe the process of introducing APL. The utility of this measure may well be accepted as a truism, but it is one which requires some clarification.
For one thing, an ad hoc notation which provided exactly the functions needed for some particular topic would be easy to introduce in context. It is necessary to ask further questions concerning the total bulk of notation required, the degree of structure in the notation, and the degree to which notation introduced for a specific purpose proves more generally useful.
Secondly, it is important to distinguish the difficulty of describing and of learning a piece of notation from the difficulty of mastering its implications. For example, learning the rules for computing a matrix product is easy, but a mastery of its implications (such as its associativity, its distributivity over addition, and its ability to represent linear functions and geometric operations) is a different and much more difficult matter.
Indeed, the very suggestiveness of a notation may make it seem harder to learn because of the many properties it suggests for explorations. For example, the notation +.× for matrix product cannot make the rules for its computation more difficult to learn, since it at least serves as a reminder that the process is an addition of products, but any discussion of the properties of matrix product in terms of this notation cannot help but suggest a host of questions such as: Is ∨.∧ associative? Over what does it distribute? Is b∨.∧c ←→ ⍉(⍉c)∨.∧⍉b a valid identity?
5.3 Extensions to APL
In order to ensure that the notation used in this paper is well-defined and widely available on existing computer systems, it has been restricted to current APL as defined in [4] and in the more formal standard published by STAPL, the ACM SIGPLAN Technical Committee on APL [17, p.409]. We will now comment briefly on potential extensions which would increase its convenience for the topics treated here, and enhance its suitability for the treatment of other topics such as ordinary and vector calculus.
One type of extension has already been suggested by showing the execution of an example (roots of a polynomial) on an APL system based on complex numbers. This implies no change in function symbols, although the domain of certain functions will have to be extended. For example, |x will give the magnitude of complex as well as real arguments, +x will give the conjugate of complex arguments as well as the trivial result it now gives for real arguments, and the elementary functions will be appropriately extended, as suggested by the use of * in the cited example. It also implies the possibility of meaningful inclusion of primitive functions for zeros of polynomials and for eigenvalues and eigenvectors of matrices.
A second type also suggested by the earlier sections includes functions defined for particular purposes which show promise of general utility. Examples include the nub function N , defined by D.3, and the summarization function S , defined by D.4. These and other extensions are discussed in [18]. McDonnell [19, p.240] has proposed generalizations of and and or to non-booleans so that a∨b is the GCD of a and b, and a^b is the LCM. The functions gcd and lcm defined in Section 3 could then be defined simply by gcd:∨/⍵ and lcm:^/⍵ .A more general line of development concerns operators, illustrated in the preceding sections by the reduction, inner-product, and outer-product. Discussions of operators now in APL may be found in [20] and in [17, p.129], proposed new operators for the vector calculus are discussed in [17, p.47], and others are discussed in [18] and in [17, p.129].
5.4 Mode of Presentation
The treatment in the preceding sections concerned a set of brief topics, with an emphasis on clarity rather than efficiency in the resulting algorithms. Both of these points merit further comment.
The treatment of some more complete topic, of an extent sufficient for, say, a one- or two-term course, provides a somewhat different, and perhaps more realistic, test of a notation. In particular, it provides a better measure of the amount of notation to be introduced in normal course work.
Such treatments of a number of topics in APL are available, including: high school algebra [6], elementary analysis [5], calculus, [13], design of digital systems [21], resistive circuits [10], and crystallography [22]. All of these provide indications of the ease of introducing the notation needed, and one provides comments on experience in its use. Professor Blaauw, in discussing the design of digital systems [21], says that “APL makes it possible to describe what really occurs in a complex system”, that “APL is particularly suited to this purpose, since it allows expression at the high architectural level, at the lowest implementation level, and at all levels between”, and that “...learning the language pays of (sic) in and outside the field of computer design”.
Users of computers and programming languages are often concerned primarily with the efficiency of execution of algorithms, and might, therefore, summarily dismiss many of the algorithms presented here. Such dismissal would he short-sighted, since a clear statement of an algorithm can usually be used as a basis from which one may easily derive more efficient algorithm. For example, in the function step of section 3.2, one may significantly increase efficiency by making substitutions of the form b⌹m for (⌹m)+.×b , and in expressions using +/c×x*¯1+⍳⍴c one may substitute x⊥⌽c or, adopting an opposite convention for the order of the coefficients, the expression x⊥c .
More complex transformations may also be made. For example, Kerner’s method (C.3) results from a rather obvious, though not formally stated, identity. Similarly, the use of the matrix ⍺ to represent permutations in the recursive function r used in obtaining the depth first spanning tree (C.4) can be replaced by the possibly more compact use of a list of nodes, substituting indexing for inner products in a rather obvious, though not completely formal, way. Moreover, such a recursive definition can be transformed into more efficient non-recursive forms.
Finally, any algorithm expressed clearly in terms of arrays can be transformed by simple, though tedious, modifications into perhaps more efficient algorithms employing iteration on scalar elements. For example, the evaluation of +/x depends upon every element of x and does not admit of much improvement, but evaluation of ∨/b could stop at the first element equal to 1 , and might therefore be improved by an iterative algorithm expressed in terms of indexing.
The practice of first developing a clear and precise definition of a process without regard to efficiency, and then using it as a guide and a test in exploring equivalent processes possessing other characteristics, such as greater efficiency, is very common in mathematics. It is a very fruitful practice which should not be blighted by premature emphasis on efficiency in computer execution.
Measures of efficiency are often unrealistic because they concern counts of “substantive” functions such as multiplication and addition, and ignore the housekeeping (indexing and other selection processes) which is often greatly increased by less straightforward algorithms. Moreover, realistic measures depend strongly on the current design of computers and of language embodiments. For example, because functions on booleans (such as ^/b and ∨/b) are found to be heavily used in APL, implementers have provided efficient execution of them. Finally, overemphasis of efficiency leads to an unfortunate circularity in design: for reasons of efficiency early programming languages reflected the characteristics of the early computers, and each generation of computers reflects the needs of the programming languages of the preceding generation.
Acknowledgments. I am indebted to my colleague A.D. Falkoff for suggestions which greatly improved the organization of the paper, and to Professor Donald McIntyre for suggestions arising from his reading of a draft.
Appendix A. Summary of Notation
| f⍵ | SCALAR FUNCTIONS | ⍺f⍵ | ||||||
| ⍵ | Conjugate | + | Plus | |||||
| 0-⍵ | Negative | - | Minus | |||||
| (⍵>0)-⍵<0 | Signum | × | Times | |||||
| 1÷⍵ | Reciprocal | ÷ | Divide | |||||
| ⍵⌈-⍵ | Magnitude | | | Residue | ⍵-⍺×⍵⍵÷⍺+⍺=0 | ||||
| Integer part | Floor | p | Minimum | (⍵×⍵<⍺)+⍺×⍵≥⍺ | ||||
| - -⍵ | Ceiling | ⌈ | Maximum | -(-⍺)--⍵ | ||||
| 2.71828...*⍵ | Exponential | * | Power | ×/⍵⍴⍺ | ||||
| Inverse of *⍵ | Natural log | ⍟ | Logarithm | (⍟⍵)÷⍟⍺ | ||||
| ×/1+⍳⍵ | Factorial | ! | Binomial | (!⍵)÷(!⍺)×!⍵-⍺ | ||||
| 3.14159...x⍵ | Pi times | ○ | ||||||
| Boolean: | ∨ ⍱ ~ (and, or, not-and, not-or, not) | |
| Relations: | < ≤ = ≥ > ≠ (⍺r⍵ is 1 if relation r holds) |
| Sec. Ref. | v←→2 3 5 m←→1 2 3 4 5 6 | |||
| Integers | 1 | ⍳5←→1 2 3 4 5 | ||
| Shape | 1 | ⍴v←→3 ⍴m←→2 3 2 3⍴⍳6←→m 2⍴4←→4 4 | ||
| Catenation | 1 | v,v←→2 3 5 2 3 5 m,m←→1 2 3 1 2 3 4 5 6 4 5 6 |
||
| Ravel | 1 | ,m←→1 2 3 4 5 6 | ||
| Indexing | 1 | v[3 1]←→5 2 m[2;2]←→5 m[2;]←→4 5 6 | ||
| Compress | 3 | 1 0 1/v←→2 5 0 1⌿m←→4 5 6 | ||
| Take, Drop | 1 | 2↑v←→2 3 ¯2↑v←→1↓v←→3 5 | ||
| Reversal | 1 | ⌽v←→5 3 2 | ||
| Rotate | 1 | 2⌽v←→5 2 3 ¯2⌽v←→3 5 2 | ||
| Transpose | 1,4 | ⍉⍵ reverses axes ⍺⍉⍵ permute axes | ||
| Grade | 3 | ⍋3 2 6 2←→2 4 1 3 ⍒3 2 6 2←→3 1 2 4 | ||
| Base value | 1 | 10⊥v←→235 v⊥v←→50 | ||
| &inverse | 1 | 10 10 10⊤235←→2 3 5 v⊤50←→2 3 5 | ||
| Membership | 3 | v∊3←→0 1 0 v∊5 2←→1 0 1 | ||
| Inverse | 2,5 | ⌹⍵ is matrix inverse ⍺⌹⍵←→(⌹⍵)+.×⍺ | ||
| Reduction | 1 | +/v←→10 +/m←→6 15 +⌿m←→5 7 9 | ||
| Scan | 1 | +\v←→2 5 10 +\m←→2 3⍴1 3 6 4 9 15 | ||
| Inner product | 1 | +.× is matrix product | ||
| Outer product | 1 | 0 3∘.+1 2 3←→m | ||
| Axis | 1 | f[i] applies f along axis i |
Appendix B. Compiler from Direct to Canonical Form
This compiler has been adapted from [22, p.222]. It will not handle definitions which include ⍺ or : or ⍵ in quotes. It consists of the functions fix and f9 , and the character matrices c9 and a9 :
fix
0⍴⎕fx f9 ⍞
d←f9 e;f;i;k
f←(,(e='⍵')∘.≠5↑1)/,e,(⌽4,⍴e)⍴' y9 '
f←(,(f='⍺')∘.≠5↑1)/,f,(⌽4,⍴f)⍴' x9 '
f←1↓⍴d←(0,+/¯6,i)↓(-(3×i)++\i←':'=f)⌽f,(⌽6,⍴f)⍴' '
d←3⌽c9[1+(1+'⍺'∊e),i,0;],⍉d[;1,(i←2↓⍳f),2]
k←k+2×k<1⌽k←i∧k∊(>⌿1 0⌽'←⎕'∘.=e)/k←+\~i←e∊a9
f←(0,1+⍴e)⌈⍴d←d,(f,⍴e)↑⍉0 ¯2↓k⌽' ',e,[1.5]';'
d←(f↑d),[1]f[2] '⍝',e
c9 a9
z9← 012345678
y9z9← 9abcdefgh
y9z9←x9 ijklmnopq
)/3→(0=1↑, rstuvwxyz
→0,0⍴z9← ABCDEFGHI
JKLMNOPQR
STUVWXYZ⎕
Example:
fix
fib:z,+/¯2↑z←fib⍵-1:⍵=1:1
fib 15
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610
⎕cr 'fib'
z9←fib y9;z
→(0=1↑,y9=1)/3
→0,0⍴z9←1
z9←z,+/¯2↑z←fib y9-1
⍝fib:z,+/¯2↑z←fib⍵-1:⍵=1:1
References
| 1. | Boole, G. An Investigation of the Laws of Thought, Dover Publications, N.Y., 1951. Originally published in 1954 by Walton and Maberly, London and by MacMillan and Co., Cambridge. Also available in Volume II of the Collected Logical Works of George Boole, Open Court Publishing Co., La Salle, Illinois, 1916. | |
| 2. | Cajori, F. A History of Mathematical Notations, Volume II, Open Court Publishing Co., La Salle, Illinois, 1929. | |
| 3. | Falkoff, A.D., and Iverson, K.E. The Evolution of APL, Proceedings of a Conference on the History of Programming Languages, ACM SIGPLAN, 1978. | |
| 4. | APL Language, Form No. GC26-3847-4, IBM Corporation. | |
| 5. | Iverson, K.E. Elementary Analysis, APL Press, Pleasantville, N.Y., 1976. | |
| 6. | Iverson, K.E. Algebra: an algorithmic treatment, APL Press, Pleasantville, N.Y., 1972. | |
| 7. | Kerner, I.O. Ein Gesamtschrittverfahren zur Berechnung der Nullstellen von Polynomen, Numerische Mathematik, Vol. 8, 1966, pp. 290-294. | |
| 8. | Beckenbach, E.F., ed. Applied Combinatorial Mathematics, John Wiley and Sons, New York, N.Y., 1964. | |
| 9. | Tarjan, R.E, Testing Flow Graph Reducibility, Journal of Computer and Systems Sciences, Vol. 9 No. 3, Dec. 1974. | |
| 10. | Spence, R. Resistive Circuit Theory, APL Press, Pleasantville, N.Y., 1972. | |
| 11. | Iverson, K.E. A Programming Language, John Wiley and Sons, New York, N.Y., 1962. | |
| 12. | Iverson, K.E. An Introduction to APL for Scientists and Engineers, APL Press, Pleasantville, N.Y. | |
| 13. | Orth, D.L. Calculus in a new key, APL Press, Pleasantville, N.Y., 1976. | |
| 14. | Apostol, T.M. Mathematical Analysis, Addison Wesley Publishing Co., Reading, Mass., 1957. | |
| 15. | Jolley, L.B.W. Summation of Series, Dover Publications, N.Y. | |
| 16. | Oldham, K.B., and Spanier, J. The Fractional Calculus, Academic Press, N.Y., 1974. | |
| 17. | APL Quote Quad, Vol. 9, No. 4, June 1979, ACM STAPL. | |
| 18. | Iverson, K.E., Operators and Functions, IBM Research Report RC 7091, 1978. | |
| 19. | McDonnell, E.E., A Notation for the GCD and LCM Functions, APL 75, Proceedings of an APL Conference, ACM, 1975. | |
| 20. | Iverson, K.E., Operators, ACM Transactions on Programming Languages And Systems, October 1979. | |
| 21. | Blaauw, G.A., Digital System Implementation, Prentice-Hall, Englewood Cliffs, N.J., 1976. | |
| 22. | McIntyre, D.B., The Architectural Elegance of Crystals Made Clear by APL, An APL Users Meeting, I.P. Sharp Associates, Toronto, Canada, 1978. |
1979 ACM Turing Award Lecture
Delivered at ACM ’79, Detroit, Oct. 29, 1979
The 1979 ACM Turing Award was presented to Kenneth E. Iverson by Walter Carlson, Chairman of the Awards Committee, at the ACM Annual Conference in Detroit, Michigan, October 29, 1979.
In making its selection, the General Technical Achievement Award Committee cited Iverson for his pioneering effort in programming languages and mathematical notation resulting in what the computing field now knows as APL. Iverson’s contributions to the implementation of interactive systems, to the educational uses of APL, and to programming language theory and practice were also noted.
Born and raised in Canada, Iverson received his doctorate in 1954 from Harvard University. There he served as Assistant Professor of Applied Mathematics from 1955-1960. He then joined International Business Machines, Corp. and in 1970 was named an IBM Fellow in honor of his contribution to the development of APL.
Dr. Iverson is presently with I.P. Sharp Associates in Toronto. He has published numerous articles on programming languages and has written four books about programming and mathematics: A Programming Language (1962), Elementary Functions (1966), Algebra: An Algorithmic Treatment (1972), and Elementary Analysis (1976).
Errata
| • | In Section 0, in the last sentence of item (c), it should be “preceding” instead of “preceeding”. | |
| • | In Section 1, in the last sentence, it should be “equivalence” instead of “equivalance”. | |
| • | In Section 1.2, in the paragraph following the first example, it should be “similarity” instead of “similiarity”. | |
| • | In Section 1.2 and Section 1.5, it should be “De Morgan” instead of “DeMorgan” (four occurrences). | |
| • | In Section 1.3, in the paragraph following the inner product examples involving p and q it should be “transshipment points” instead of “transhipment points” (two occurrences). | |
| • | In Section 1.4, in paragraph 4, it should be “Similarly” instead of “Similiarly”. | |
| • | In Section 1.5, in the paragraph following the proof of A.3, the second sentence should read “the value of bc 0” instead of “the value of BC 0” . | |
| • | In Section 1.5, in the proof of A.5, the annotation for line 7 should be “~ distributes over ,” instead of “∨ distributes over ,” . | |
| • | In Section 2.4, in the paragraph before the formula B.5, it should be “by the matrix j∘.-j” instead of “by the matrix j∘-j” . | |
| • |
In Section 3.3, the definition of mf should read:
mf:⍵[,1;],[1]x+⍵[(1↑⍴x)⍴1;]≤x←mf 1 0↓⍵:0=1↑⍴⍵:⍵ instead of mf:⍵[,1;],[1]x+⍵[(1 ⍴x)⍴1;]≤x←mf 1 0↓⍵:0=1↑⍴⍵:⍵ | |
| • | In Section 3.4, in the paragraph introducing in-degree and out-degree, the boolean vector b should be defined as b←∨/(⍳1↑⍴c)∘.=l instead of b←∨/(⍳1⍴c)∘.=l . | |
| • | In Section 4.3, the opening sentence should have only one “and”; that is, it should be “the definition and use” instead of “the definition and and use”. | |
| • | In Section 4.8, Note 2 should read v∘.×w instead of v∘×w . | |
| • | In Section 5.1, in the last sentence of the paragraph following Horner’s expression for polynomial evaluation, it should be “unambiguous” instead of “unambigious”. | |
| • | In Section 5.4, in paragraph 3, it should say “calculus [13],” instead of “calculus, [13],”. | |
| • | In Appendix A, the expression for Residue should be ⍵-⍺×⌊⍵÷⍺+⍺=0 instead of ⍵-⍺×⍵⍵÷⍺+⍺=0 | |
| • | In Appendix A, the symbol for Floor/Minimum should be ⌊ instead of p . | |
| • | In Appendix A, the expression for Ceiling should be -⌊-⍵ instead of - -⍵ and the expression for Maximum should be -(-⍺)⌊-⍵ instead of -(-⍺)--⍵ . | |
| • | In Appendix A, the expression for Factorial should be ×/⍳⍵ instead of ×/1+⍳⍵ . | |
| • | In Appendix A, the list of boolean functions should be ∧ ∨ ⍲ ⍱ ~ instead of ∨ ⍱ ~ | |
| • | In Appendix A, the “Sec. Ref.” for ⊥ should be 5 instead of 1. | |
| • |
In Appendix B, the last line of the function f9 should read
d←(f↑d),[1]f[2]↑'⍝',e instead of d←(f↑d),[1]f[2] '⍝',e | |
| • | Reference 6 should be Algebra: An Algorithmic Treatment instead of Algebra: an algorithmic treatment. | |
| • | Reference 13 should be Calculus in a New Key instead of Calculus in a new key. | |
| • | Reference 15 (Jolley’s Summation of Series) dates from 1961. |
First appeared in the Communications of the ACM, Volume 23, Number 8, 1980-08.
| created: | 2009-02-16 15:15 |
| updated: | 2018-06-22 18:50 |